






04
JulData Wrangling in Data Science
02 Aug 2025
Advanced
3.17K Views
6 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Introduction
In the field of data science, the act of cleaning, converting, and getting ready raw data for analysis is known as "data wrangling," which is an important stage covered in the data science tutorial. It entails operations like duplication removal, processing of missing values, and data type conversion. The goal of data wrangling in data science is to make sure the data is in a format that can be used for exploration and modeling. It improves data quality and dependability by correcting inconsistencies and errors, enabling data scientists, upon completion of a Data Science Certification Course, to derive useful insights and reach responsible conclusions. In the field of data science, precise analysis and interpretation are made possible by effective data wrangling, which is crucial for obtaining useful information from a variety of data sources.
What is Data Wrangling in Data Science?
Any data science effort must begin with data wrangling. It entails preparing raw data for analysis by cleaning and converting it. This can involve operations including deleting duplicate records, adding missing entries, and changing data types. Making sure your data is correct, consistent, and in understandable manner is the aim of data wrangling in data science.
Read More - Top Data Science Interview Questions
Importance of Data Wrangling in data science
Data wrangling is essential to data science because it makes it easier to glean insightful information from unstructured data. The following important information emphasizes the Importance of Data Wrangling :
- Data Quality: By correcting discrepancies, mistakes, and missing values, data wrangling enhances data quality and ensures accurate and trustworthy analysis.
- Data Preparation: It converts unusable data from the raw state into one that is acceptable for data science modeling, data science exploration , and data science visualization.
- Feature engineering: Data wrangling in data science makes it possible to extract additional features from existing data, improving the prediction ability of machine learning models.
- Data Integration: Data integration is the process of bringing together data from several sources to create a comprehensive picture and allow for extensive analysis.
- Efficiency: Data wrangling saves both money and time by automating repetitive operations, allowing data scientists to concentrate on more in-depth analysis and interpretation.
- Making decisions: Clear, well-prepared data allows for educated choices, which improves strategy and yields better corporate results.
- Data Understanding: Data scientists can obtain a deeper understanding of the data by detecting patterns, connections, and anomalies that lead to insights through data wrangling.
- Reproducibility: Transparency and reproducibility are promoted in data science workflows by properly documented data wrangling methods, which make it possible to repeat data modification activities.
Benefits of Data Wrangling
Data wrangling has lots of benefits. Your data can be cleaned and made ready so that you can:
- Boost the precision of your analysis
- Automating routine tasks can help you save time.
- In your data, you can quickly spot patterns and trends.
- Make sure your findings are trustworthy and correct.
Data Wrangling Definition
Cleaning, manipulating, and getting ready raw data for analysis is known as data wrangling. This can involve operations including deleting duplicate records, adding missing entries, and changing data types. Making ensuring your data is in a format that is simple to use and accurately represents the data you're seeking to analyze is the aim of data wrangling.
Data Wrangling Techniques
Data wrangling is possible using a variety of methods. Typical methods include the following:
- Removing duplicates: Duplicate rows or columns in your data must be found and eliminated as part of the duplicate removal process.
- Filling in missing values: Finding any values that are missing in your information and replacing them with relevant ones constitutes the process of filling in the gaps.
- Data conversion: This entails changing the kind of data (for instance, changing words into numbers).
- Filtering data: Data filtering is the process of deleting any information that isn't pertinent to your study.
- Aggregating data: Data aggregation is the process of integrating several rows or columns of information into a single row or column.
Typical Data Wrangling Workflow
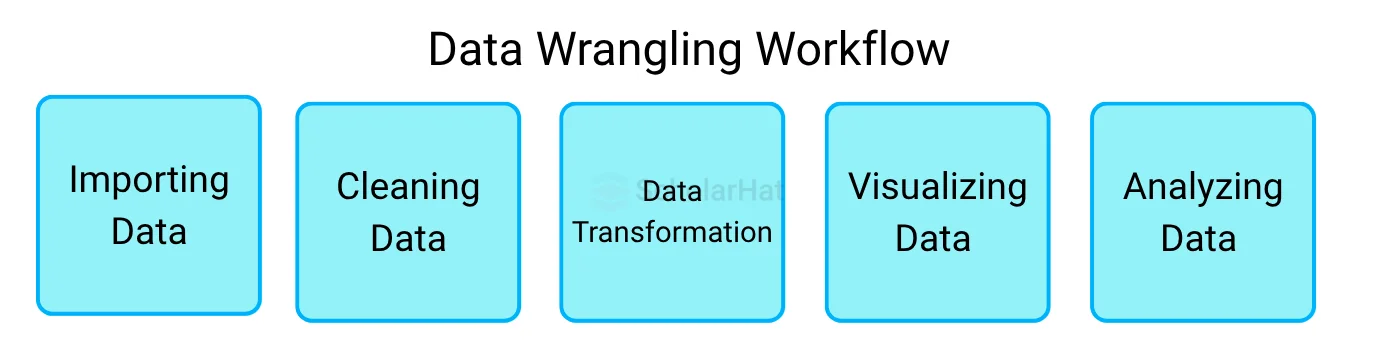
The following steps could be included in a typical data-wrangling workflow:
- Importing data: Adding raw data to a software program so it may be analyzed is known as "importing" data.
- Cleaning data: Data cleaning is the process of locating and correcting flaws and discrepancies in your data.
- Data transformation: This entails putting your data into a format that is simple to use, such as changing text to numbers.
- Visualizing data: Making charts or graphs to help you understand your data visually is known as data visualization.
- Analyzing data: Data analysis is the process of finding patterns and trends in your data through the use of statistical methods.
Data Wrangling Tools
Data wrangling is the process of cleaning, transforming, and integrating data from different sources into a format that is suitable for analysis. Data wrangling can be done using a variety of technologies. Several well-liked data wrangling tools are:
- OpenRefine: Data cleansing and transformation can be done with the help of OpenRefine, a free open-source program.
- Trifacta: This is a for-profit technology that streamlines data manipulation procedures through the use of machine learning.
- Excel: Excel is a well-known spreadsheet program that may be used for simple data manipulation tasks.
- Python: Python is a computer language with a large number of libraries for manipulating data that is frequently used for data analysis.
Best Practices for Data Wrangling
You must keep to a few recommended practices to get the most out of your data-wrangling efforts. These consist of:
- Making a process record: Record your data-wrangling procedures so you can later duplicate your effort.
- The use of version control: To keep track of modifications to your data and analysis, use a version control system like Git.
- Executing routine tasks automatically: Scripts and other tools can be used to automate repetitive processes.
- Verifying your work: Make sure your data and interpretation are accurate and consistent by double-checking them.
Summary
In data science, cleaning, converting, and getting ready raw data for analysis are all parts of the process known as "data wrangling." It guarantees the accuracy of the data for exploration and modeling, improving dependability and facilitating insightful conclusions. It supports the importance of Data Wrangling such as data integration, feature engineering, and effective decision-making. OpenRefine, Trifacta, Excel, & Python are all well-liked data wrangling tools commonly covered in a Data Science Course. The best practices include task automation, version control, documentation of processes, and accuracy assurance.