



13
MarExperimental Design in Data Science - Design Flow, Principles & Examples
02 Aug 2025
Beginner
9.73K Views
8 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Introduction
Experimental design is the process of planning, carrying out, and analyzing experiments to test a hypothesis. Data science fundamentally involves making decisions based on data. Maximizing the amount of data that can be gathered from an experiment while minimizing the time, costs, and mistakes that are involved is the goal of Data Science Certification Course and experimental design.Therefore, it's essential to Learn Data Science in order to use data effectively and make wise selections during the experimental design process.
What is Experimental Design?
A methodical technique for organizing and carrying out tests is known as experimental design. It entails determining the factors that must be investigated, selecting the right sample size, and planning an experiment that will produce precise and trustworthy results. Many disciplines, including engineering, psychology, agriculture, and medicine, use experimental design.
Experimental Design Flow
In data science, the experimental design flow often adheres to a standardized procedure to guarantee careful preparation, execution, and evaluation of experiments. Here is a general description of the data science experimental design flow:
Indicate what the research question is. Clearly define the research topic or problem statement that your experiment will attempt to solve. This will serve as the design's compass throughout.
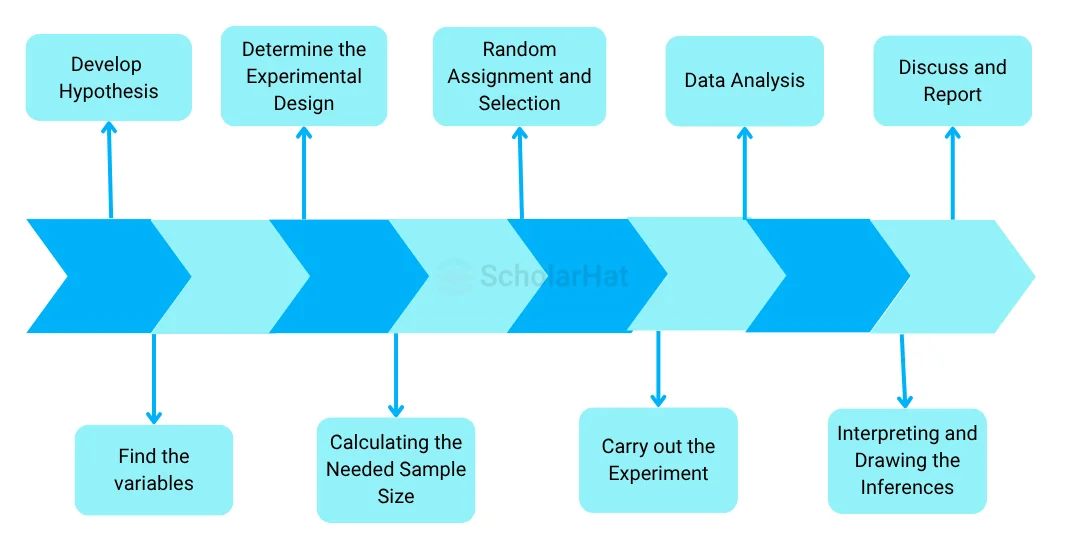
- Develop Hypotheses: Create precise hypotheses that outline the anticipated differences or correlations between variables. These hypotheses ought to be testable and give your experiment a distinct focus.
- Find the variables: Decide which independent variables you'll change or control and which dependent variables you'll measure or watch. Think about any potential confounding factors that might need to be taken into consideration throughout the experiment.
- Determine the Experimental Design: Depending on the nature of your research issue and the resources at your disposal, choose an acceptable experimental design. Factorial designs, randomized block designs, totally randomized designs, and more are examples of common designs. Each design has its own benefits and factors to take into account.
- Calculating the Needed Sample Size: Calculate the necessary sample size to generate adequate statistical power and identify significant effects. Think about things like the effect magnitude, the desired extent of significance, and anticipated data variability.
- Random Assignment and Selection: To reduce bias and confounding effects, randomly assign individuals or treatments to the various experimental conditions. Randomization makes ensuring that the groups are identical and that any effects seen are a result of changing the independent variable(s).
- Carry out the experiment: Follow the instructions, and gather the data. Maintain integrity in collecting data across all experimental circumstances by adhering to the defined methodologies.
- Data Analysis: Use the acquired data for appropriate statistical analysis to evaluate the hypotheses and develop conclusions. Depending on the experimental design and research issue, this may require different procedures including hypothesis testing, regression analysis, ANOVA, and other statistical methods.
- Interpreting and Drawing Inferences: Examine the outcomes and interpret them in regard to the study topic. Consider the data's practical ramifications while evaluating the statistically significant nature of the observed effects.
- Discuss and Report: Give a clear and succinct presentation of the design of the experiment, methodology, findings, and conclusions. To enable reproducibility and transparency, the experiment should be thoroughly documented.
Read More - Data Science Interview Questions
Principles of Experimental Design
The fundamentals of this design determine whether an experiment is successful. These principles of experimental design consist of:
- Replication: Replication is the practice of experimenting again to make sure the outcomes are reliable. This rule guarantees that the outcomes are not the result of coincidence or randomness.
- Randomization: Randomization is the technique of dividing people into various treatment groups at random. This approach guarantees that prejudice or innate variations between the groups did not affect the outcomes.
- Control: A control group is a group that has not received any treatment, hence a control group is used to compare the treatment group's findings to its outcomes. This approach guarantees that the treatment is the reason that any other factors are to blame for the outcomes.
- Blocking: Grouping participants according to a particular trait that could have an impact on the results is known as blocking. This principle makes sure that the results aren't affected by group differences.
Understanding the Experimental Design Flow
Several steps in this design flow are essential to an experiment's success. These procedures consist of:
- Formulating a hypothesis: Coming up with a theory Making a hypothesis is the first stage in this design process. A hypothesis is a claim that foretells the result of an experiment based on earlier findings or observations.
- The variables to be identified are: Finding the variables that need to be tested is the next stage. Independent, dependent, and controlling variables are different types of variables.
- Making the experiment's design: The experiment's design comes next. Choosing the right sample size, the treatment group, the control group, & the variables to be measured are all necessary steps in this process.
- Executing the experiment: Executing the experiment is the fourth step. This entails gathering information and making sure the experiment is carried out in a controlled setting.
- Analyzing the data: Examining the data is the last phase. To assess the significance of the results, statistical approaches must be used.
Confounder
A variable that is connected to both the dependent and independent variables but is not a component of the hypothesis being tested is referred to as a confounder. Confounding factors have the potential to skew an experiment's findings and provide false conclusions. Confounding variables must be understood in experimental design and taken into account when creating the experiment.
Examples of Experimental Design in Data Science
Several data science topics employ experimental design. Here are a few examples:
- A/B Testing: A/B testing is an experiment that compares the performance of two different iterations of a product. This is frequently applied to product development, marketing, and website design.
- Clinical Trials: To assess the safety and efficacy of new medications or medical procedures, clinical trials test them on human volunteers.
- Agricultural Experiments: Agricultural experiments examine novel farming methods or products to ascertain their impact on crop productivity and quality.
Experimental Design Software and Tools
You can create and carry out experiments with the aid of a variety of applications and tools. Here are a few examples:
- R: Data science often uses the statistical programming language R. It offers many packages that are useful for designing and analyzing experiments.
- SAS: SAS is a popular statistical software program in data science. It has many tools that can be used for the planning and analysis of experiments.
- MATLAB: MATLAB is a program for numerical computation that is popular in data science. It has many tools that can be used for the planning and analysis of experiments.
Challenges in Experimental Design and How to Overcome Them
Due to a variety of issues, including sample size, environmental constraints, and ethical considerations, experimental design can be difficult. The following advice can help you get through these obstacles:
- Sample Size: When designing an experiment, the right sample size is essential. To get around this problem, you can calculate the necessary sample size for your experiment using statistical power analysis.
- Environmental Aspects: The environment can have an impact on an experiment's outcomes. You can run your experiment in a controlled setting to get around this difficulty.
- Ethics-Related Matters: Designing an experiment must take ethical issues into account, especially when using human beings. You can employ the ethical standards established by governing authorities like the Institutional Review Board (IRB) to solve this difficulty.
Best Practices for Conducting Experimental Design
Here are some best practices to follow to make sure your experiment is successful:
- Start with a clear hypothesis: You may construct an experiment that will produce precise and trustworthy results by beginning with a clear hypothesis.
- Use randomization as well as control groups: In experimental design, randomization, and control groups are essential. They aid in preventing bias and underlying group differences from influencing the outcomes.
- Utilize the correct statistical techniques: In experimental design, it is essential to use the proper statistical techniques. It makes sure that the outcomes are accurate and trustworthy.
Summary
A key component of data science that enables us to make data-driven decisions is experimental design. You may design experiments that produce accurate and trustworthy findings by understanding the principles of experimental design, the experimental design flow, important terminologies, examples, software and tools, obstacles, key terminology like confounder, and best practices. Enrolling in a Data Science Course can provide you with comprehensive knowledge of experimental design techniques and their applications. Always begin with a specific hypothesis, employ control and randomization groups, and apply the proper statistical techniques. You may be certain that your experiment is a success by adhering to these best practices.