









08
MayWhat are Data Structures - Types of Data Structures (Complete Guide)
23 Sep 2025
Beginner
49.3K Views
26 min read

Learn with an interactive course and practical hands-on labs
Free DSA Online Course with Certification
A data structure is a storage that is used to store and organize data. Data structures are not just about storing data they determine how data can be accessed, modified, and manipulated. The choice of data structure directly affects the performance of algorithms and applications.
In this Data Structures tutorial, we will understand about What is a Data Structure, Classification of different types of data structure in which you will able to understand Primitive Data Structure (int, char, float, bool) and Non-Primitive Data Structure which consist of Linear Data Structure (Array, Linked List, Stack, Queue, Deque) and Non-Linear Data Structure (Tree, Graph), also you will able to know about applications, advantages and disadvantages of the various types of data structure. By 2027, 80% of coding interviews will focus on DSA skills. Ace them with our Free Data Structures and Algorithms Course today!
What is a Data Structure?
A Data Structure is the method of storing and organizing data in the computer memory. It is the branch of Computer Science that deals with arranging such large datasets in such a manner so that they can be accessed and modified as per the requirements. In other words, a data structure is a fundamental building block for all critical operations to be performed on the data.- It is a specialized format for arranging, managing, and storing data to perform operations like searching, sorting, inserting, deleting, etc.
- Data structures give us the possibility to manage large amounts of data efficiently for uses such as large databases and internet indexing services.
- Data structures are essential ingredients in creating fast and powerful algorithms.
- There are different basic and advanced types of data structures that are used in almost every program or software system that has been developed.
Basic Terminologies in Data Structures
- Data: It is a value or a collection of values that gives you contextual information. E.g. 30 degrees C temperature of the data, roll nos of students, etc.
- Database: It is a record of data. It is stored on a hard disk as compared to data structures that get stored in computer memory i.e. RAM.
- Elementary Items: They are data items that are unable to be divided into sub-items. e.g. roll no. of a student.
- Entity: It is a class of certain objects.
- Attributes: They are the specific properties of an entity.
Read More - Data Structure Interview Questions for Freshers
Classification of Data Structures

Data Structures are mainly classified into two categories:
Primitive Data structure
- They store the data of only one type i.e. built-in data types.
- Data types like
integer,float,character, andbooleanscome in this category.
Non- Primitive Data structure
- They can store the data of more than one type i.e. derived data types.
- Data types like
arrays,linked lists,trees, etc. come in this category. - Non-Primitive Data Structures are data structures derived from Primitive Data Structures.
- They further divided into two categories:
- Linear Data Structures: The data in this data structure is arranged in a sequence, one after the other i.e. each element appears to be connected linearly. Based on the memory allocation, the Linear Data Structures are again classified into two types: Static Data Structures and Dynamic Data Structures
- Non-Linear Data Structures: The data in this data structure are not arranged in a sequence. They form a hierarchy i.e. the data elements have multiple ways to connect to other elements. e.g.
treeandgraph
Primitive Data Structures
Primitive Data Structures are the most basic types of data structures that serve as the foundation for creating more complex data structures. These data types are directly supported by the computer's hardware and have a fixed size and operations that can be performed on them.
Characteristics of Primitive Data Structures
- Simple: They represent simple values and are not derived from other data structures.
- Predefined: They are predefined in most programming languages and are handled directly by the machine's CPU.
- Efficient: They offer simple operations and are memory-efficient because they directly store the data.
Types of Primitive Data Structures
- Integer
- Float (or Double)
- Character (Char)
- Boolean
- Pointers
1. Integer
An Integer data type that represents whole numbers, both positive and negative, without any fractional part.
- Example:
int a = 5; - Operations: Arithmetic operations like addition, subtraction, multiplication, division.
2. Float (or Double)
A Float data type is used to represent numbers with fractional parts (decimals).
- Example:
float b = 5.75; - Operations: Arithmetic operations, rounding, and truncation.
3. Character (Char)
Character represents a single character (like a letter, symbol, or digit).
- Example:
char c = 'A'; - Operations: Comparison, arithmetic with ASCII values, concatenation.
4. Boolean
Boolean represents one of two values: true or false.
- Example:
bool isActive = true; - Operations: Logical operations like AND, OR, NOT.
5. String
The string is asequence of characters (used to represent text).
- Example:
string name = "John"; - Operations: Concatenation, substring extraction, length calculation.
6. Pointers (in languages like C and C++)
Pointers are variables that store the memory address of another variable.
- Example:
int *ptr = &a; - Operations: Dereferencing, address manipulation.
Advantages of Primitive Data Structures
- Efficiency: Since they are simple and directly supported by hardware, they are fast and efficient in terms of memory and processing power.
- Ease of Use: Simple and easy to understand as they don’t involve complex relationships between elements.
- Fixed Size: Their size is usually fixed, leading to predictable memory usage.
Disadvantages of Primitive Data Structures
- Limited Functionality: As they represent basic data types, they don’t support complex structures or operations.
- No Relationships: They do not allow representation of relationships between data, unlike complex data structures (like arrays or trees).
Applications of Primitive Data Structures
- Memory Storage: Storing basic types like numbers or text.
- Mathematical Operations: Performing basic arithmetic, and logical operations.
- Control Flow: Using Boolean values for decisions in programs (like in if-else conditions).
Non-Primitive Data Structures
Non-Primitive Data Structures are complex data structures that are built using primitive data types like int, char, float, etc.
They are designed to organize and manage large or complex data efficiently and are used to perform operations like insertion, deletion, searching, and sorting.
- Linear Data Structures
- Non-linear Data Structures
Linear Data Structures
Data structure in which data elements are arranged sequentially or linearly, where each element is attached to its previous and next adjacent elements, is called a linear data structure.
Example: Array, Stack, Queue, Linked List, etc.
Arrays
An array is a collection of elements, all of the same data type, stored in contiguous memory locations. It has a fixed size, which is specified during its creation.
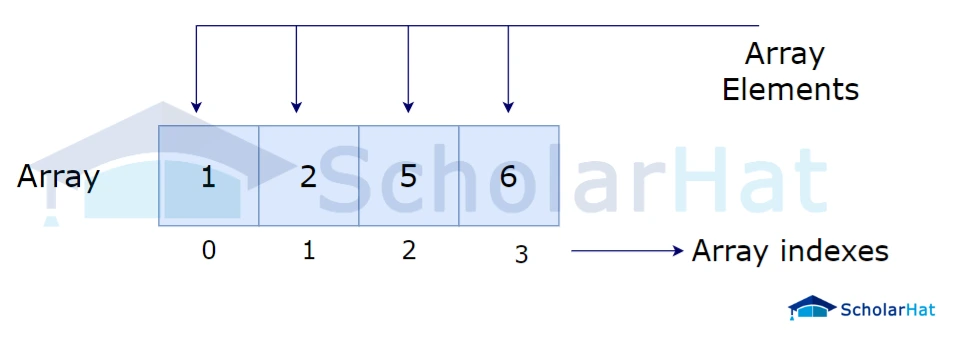
Characteristics:
- Fixed-size (cannot grow or shrink dynamically).
- Indexed collection, meaning elements are accessed using an index.
- Memory-efficient for storing large datasets of the same type.
Applications: Used to store data in a database, matrices, and images (in terms of pixels).
Operations:
- Access: Direct access to any element using its index.
- Search: Searching an element by value.
- Insert/Delete: Insertions and deletions are inefficient as elements may need to be shifted.
Advantages: Fast access via index (constant time). Simple implementation.
Disadvantages: Fixed size makes it less flexible. Insertion and deletion operations can be inefficient.
| Read More:Arrays in Data Structures |
Linked Lists
A linked list is a collection of nodes, where each node stores a data element and a reference (pointer) to the next node in the sequence. It is a dynamic data structure with no fixed size.
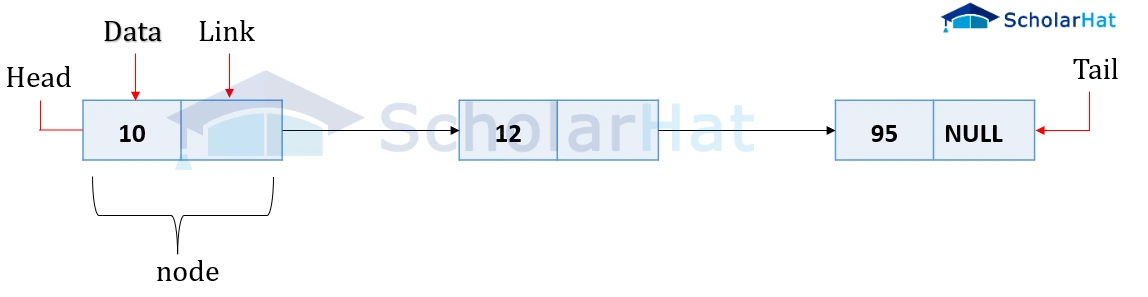
Characteristics:
- Dynamic size (can grow or shrink as needed).
- Each node points to the next, with no contiguous memory allocation.
Applications: Used in memory management systems, and implementation of stacks, queues, and graphs.
Operations:
- Traversal: Visiting each node from the head to the tail.
- Insertion/Deletion: Inserting or deleting nodes can be done efficiently by updating pointers.
Advantages: Dynamic size allows for efficient memory usage. Insertions and deletions are efficient at both ends (front or back).
Disadvantages: Sequential access (no direct access to elements by index). Extra memory is required for storing pointers.
| Read More: Linked List in Data Structures |
Stacks
A stack is a linear data structure that follows the Last-In-First-Out (LIFO) principle, where the last element added is the first one to be removed.
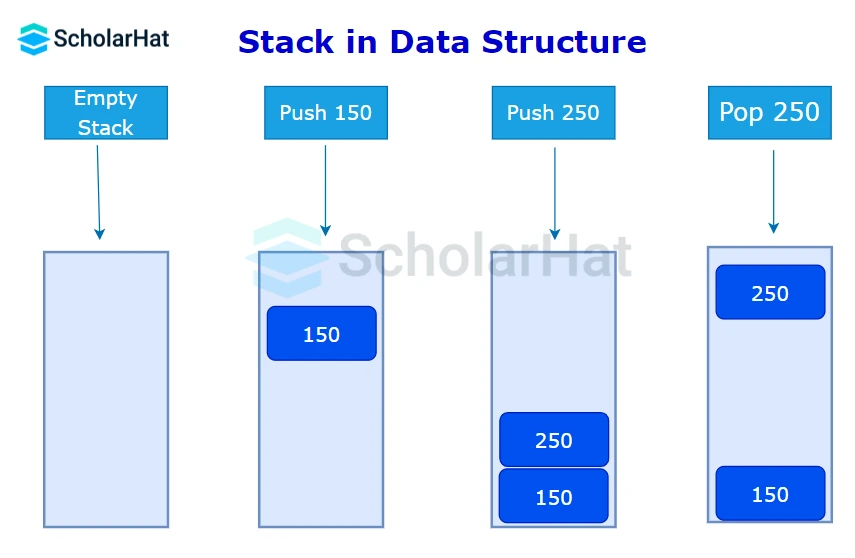
Characteristics:
- Only two operations are allowed: push (add an element to the top) and pop (remove the top element).
Applications: Function call management in recursion, expression evaluation (infix, postfix, and prefix), and undo functionality in applications.
Operations:
- Push: Add an element to the top of the stack.
- Pop: Remove the top element from the stack.
- Peek: View the top element without removing it.
Advantages: Simple and fast for certain tasks like undo operations and parsing expressions.
Disadvantages: Limited access to other elements (only the top element is accessible). Fixed-size in an array-based implementation.
| Read More: Introduction to Stack in Data Structures |
Queues
A queue is a linear data structure that follows the First-In-First-Out (FIFO) principle, where the first element added is the first one to be removed.

Characteristics:
- Operates with two main pointers: front (removes elements) and rear (adds elements).
- Efficient for processing tasks in order.
Applications: CPU scheduling, printer task scheduling, handling requests in web servers.
Operations:
- Enqueue: Add an element to the rear of the queue.
- Dequeue: Remove an element from the front of the queue.
- Peek: View the front element.
Advantages: Useful for handling tasks in a predictable order.
Disadvantages: Fixed size in static implementations. Inefficient for random access.
| Read More: Queue in Data Structures - Types & Algorithm (With Example) |
Deque (Double-Ended Queue)
Definition: A deque is a linear data structure that allows elements to be added or removed from both ends (front and rear).
Characteristics:
- Supports operations at both ends.
- More flexible than a standard queue.
Applications: Sliding window problems, caching algorithms.
Operations:
- Insert Front/Rear: Add elements at either end.
- Delete Front/Rear: Remove elements from either end.
Advantages: More flexibility than queues or stacks.
Disadvantages: Increased complexity in implementation.
Non-Linear Data Structures
Data structures where data elements are not placed sequentially or linearly are called non-linear data structures. In a non-linear data structure, we can’t traverse all the elements in a single run only.
Examples: Trees and Graphs.
Trees
A tree is a hierarchical structure that consists of nodes, with each node containing data and references to its child nodes. The topmost node is called the root, and each node can have zero or more child nodes.
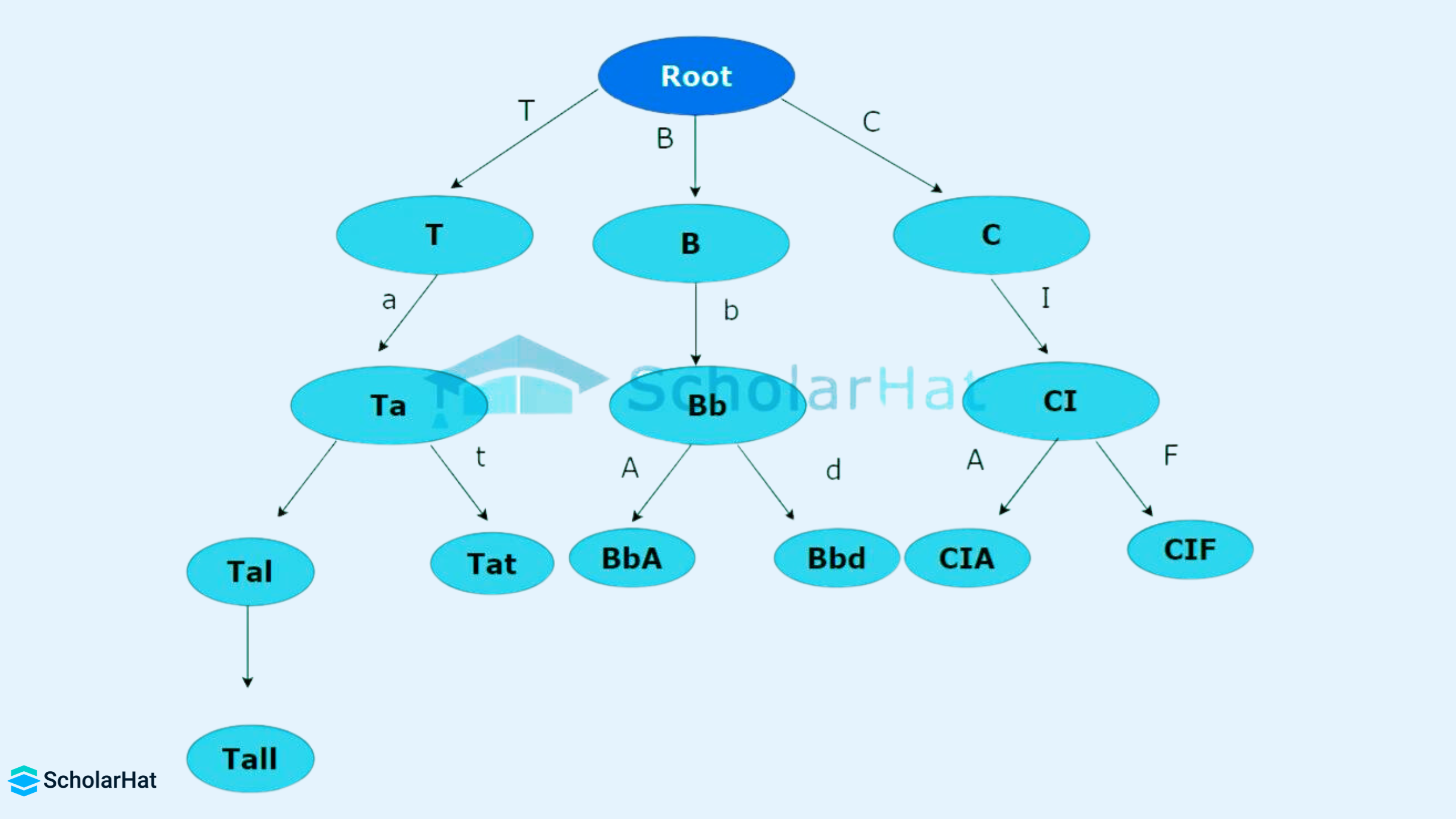
Characteristics:
- Root nodes, parent nodes,and child nodes.
- No cycles (acyclic).
- Recursive structure, as each child node can also have its own sub-tree.
Applications: File systems (directories and subdirectories), decision-making algorithms (decision trees), binary search trees for efficient searching and sorting.
Operations:
- Insertion/Deletion: Insert or delete nodes while maintaining the hierarchical structure.
- Traversal: Visiting each node (pre-order, in-order, post-order).
Advantages: Efficient searching and sorting (in balanced trees like AVL trees and red-black trees).
Disadvantages: Complex implementation, especially for balanced trees.
| Read More:Trees in Data Structures |
Graphs
A graph is a collection of nodes (vertices) and edges, where edges represent the relationships between nodes. Graphs can be directed or undirected.
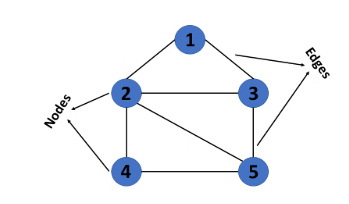
Characteristics:
- Vertices (nodes) and edges (connections between nodes).
- It can be cyclic or acyclic, directed or undirected.
Applications: Social networks (users and their connections), shortest path problems (e.g., Dijkstra's algorithm), web page linking (web graphs).
Operations:
- Add/Remove Vertices and Edges: Modify the structure of the graph.
- Traversal: Visit all nodes via BFS (Breadth-First Search) or DFS (Depth-First Search).
Advantages: Can model complex relationships effectively.
Disadvantages: Memory-intensive and complex to implement, especially for large graphs.
| Read More: What is a Graph in Data Structures |
Hash Tables
A hash table stores data in an associative manner using a hash function to map keys to values. It provides efficient lookup, insertion, and deletion.
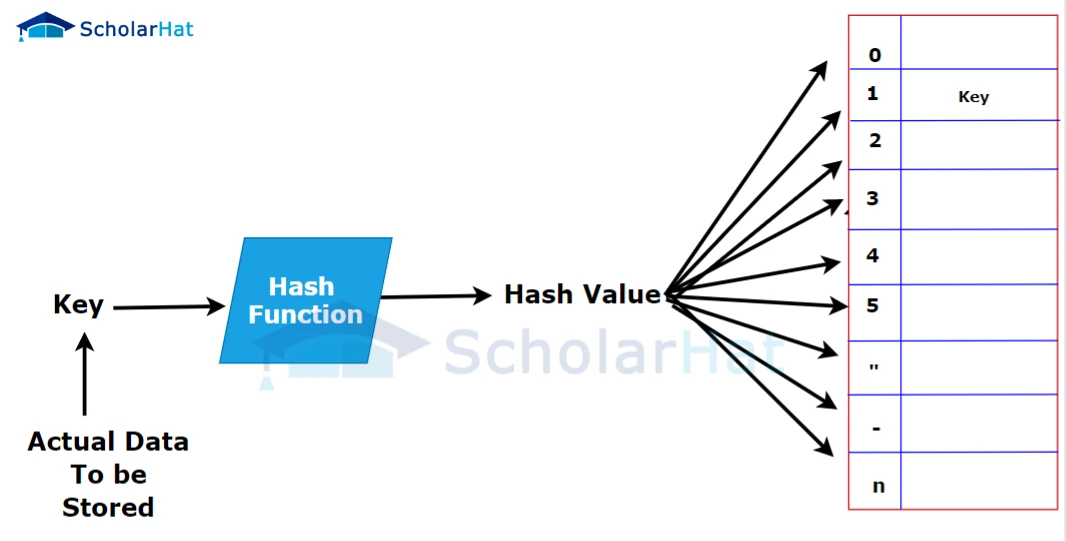
Characteristics:
- Key-value pairs.
- It uses a hash function to compute the index for storing data.
- Handles collisions through techniques like chaining or open addressing.
Applications: Caching (storing frequently accessed data), database indexing, implementing associative arrays.
Operations:
- Insert: Store a key-value pair.
- Search: Look up the value corresponding to a key.
- Delete: Remove a key-value pair.
Advantages: Fast access to data (constant time complexity in average cases).
Disadvantages: Hash collisions can reduce efficiency. Requires resizing when the load factor becomes high.
| Read More: Hash Table in Data Structures |
Linear Vs Non-linear Data Structures
| Characteristics | Linear Data Structure | Non-linear Data structure | ||
| Arrangement of data | The data is consecutively stored one after the other. | The data is stored in a non-sequential (hierarchical) manner. | ||
| Storage of data | Each data stored is directly linked to its previous and next elements. | The data is stored in a random manner or contiguous memory locations. | ||
| Layers of data | The data is arranged in a single layer. | The data is arranged in multiple layers. | ||
| Time complexity | The time required to access all the data in the data structure increases as the volume of the data increases. | The time required to access all the data in the data structure remains the same even if the volume of the data increases. | ||
| Number of traverses | The user can traverse the data structure in a single pass. | The user cannot traverse the data structure in a single pass. | ||
| Advantages | Irrespective of the volume of the data, these data structures are easy to use where the operations are simple. | Irrespective of the volume of the data, these data structures are easy to use where the operations are complex. | ||
| Memory usage | Inefficient memory usage | Efficient memory usage | ||
| Uses | Linear data structures are widely used in software development. | Non-linear data structures are widely used in Artificial intelligence, image processing, etc. | ||
| Examples | Array, Stack, Queue, Linked Lists, etc. Each of these data structures can be further subdivided into its types. | Trees, Graphs, | ||
Why learn Data Structures?
A data structure represents an Abstract Data Type (ADT) that confirms its relevance to the algorithm or application.
Data Structures allow us to organize and store data, that are significant from the management, organization, and storage perspective
A data structure helps in efficient data search and retrieval.
Data structures are the most necessary elements of many robust algorithms.
Data Structure Operations
Some of the basic operations performed on a data structure are as follows:
Traversing- Accessing or visiting each data element in a particular order in a data structure is called traversing.
Searching- It is finding the location(s) of data that satisfy one or more conditions. We have various search techniques like linear search and binary search to search for elements in a data structure.
Inserting—Inserting new data into the data structure is called insertion. Data can be inserted at the initial (first), final (last), or anywhere between the first and final locations. This operation increases the size of the data structure.
Deleting—Removing existing data elements from the data structure is called deletion. Data is deleted from the initial (first), final (last), or anywhere between the first and final locations. This operation decreases the size of the data structure.
Sorting- Arranging the data in a specified order (ascending or descending) is sorting. A user uses different techniques to sort data, viz bubble sort, shell sort, etc.
Merging- Combining the data from two data structures (or files) into a single is called merging. This operation improves the competency in searching and ascertains correct data access to the users.
Advantages of Data Structures
- Improved data organization and storage efficiency.
- Faster data retrieval and manipulation.
- Facilitates the design of algorithms for solving complex problems.
- Eases the task of updating and maintaining the data.
- Provides a better understanding of the relationships between data elements.
Disadvantages of Data structures
- Increased computational and memory overhead.
- Difficulty in designing and implementing complex data structures.
- Limited scalability and flexibility.
- Complexity in debugging and testing.
- Difficulty in modifying existing data structures.
Conclusion
Data structures are fundamental building blocks in computer science that provide efficient ways to store, organize, and manage data. They allow programmers to perform operations like insertion, deletion, searching, and sorting effectively. Choosing the right data structure is crucial for writing optimal and scalable programs. In this tutorial, you understood types of data structure in detail.
Average Java Solution Architect earns ₹35–45 LPA. Don’t let your career stall at ₹8–10 LPA—Enroll now in our Java Architect Course to fast-track your growth.
FAQs
In the programming world, Data Type is the set of quantities that belongs together and are of a similar category. Data type is used so that the compiler or interpreter of a programming language can be told about the data which is to be used.
We have seen that they can be classified into linear and non-linear data structures based on their structure, and based on their properties and functionalities, they can be classified into primitive, composite, static, dynamic, homogeneous, and heterogeneous data structures.
Data structures are a specific way of organizing data in a specialized format on a computer so that the information can be organized, processed, stored, and retrieved quickly and effectively
Take our Datastructures skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.