







13
MarUnderstanding Data Abstraction in DBMS
25 Sep 2024
Beginner
5.21K Views
8 min read

Learn with an interactive course and practical hands-on labs
Free SQL Server Online Course with Certificate - Start Today
Data Abstraction in DBMS
Abstraction in DBMS is a fundamental concept that simplifies the interaction with data by hiding the complexities of how data is stored and managed. It allows users to interact with the data without needing to know the underlying implementation details. This concept is crucial for database management systems as it improves data handling efficiency and provides a clean interface for users.
In this DBMS tutorial, we will discuss what abstraction in DBMS is, why it's important, the different levels of abstraction, examples of database abstraction, how it simplifies database design and key differences between data abstraction and data hiding.
What is Data Abstraction in DBMS?
- Data abstraction is an important concept in database management systems.
- Data abstraction is the process of hiding unwanted and irrelevant information from the end user.
- Although storing information allows the end user to obtain relevant data, the user cannot see what data is saved or how it is stored in a database.
- Data abstraction protects data from unauthorized access while obscuring implementation details.
Example
When you go to buy a smartphone, you check the features like screen size, camera quality, battery life, and brand. You don’t worry about how the internal circuits are designed or where the components are sourced from. This is similar to data abstraction in DBMS. You are only interested in the relevant features, while the underlying technical details are hidden. In this article, we will explore how data abstraction simplifies data handling by focusing on necessary information and hiding complexity.
Levels of Abstraction in DBMS
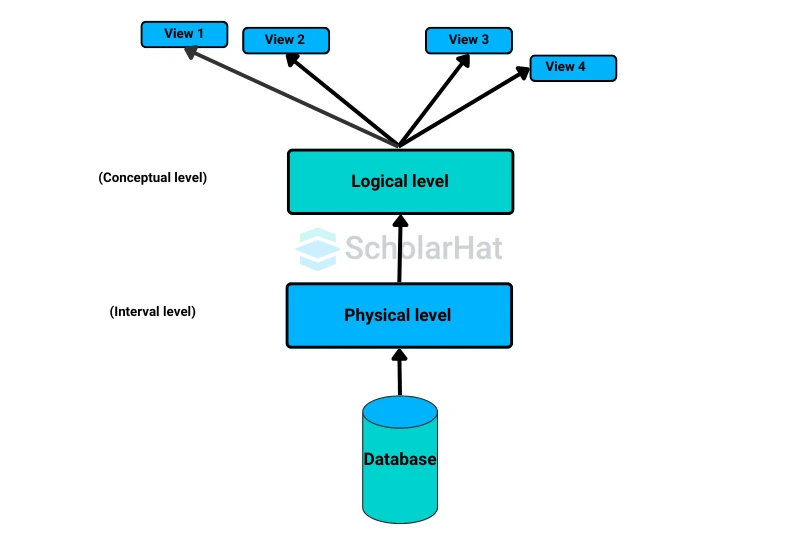
There are three levels of data abstraction in DBMS, which are described here.
1. Physical or internal level
2. Logical or conceptual level
3. View or external level
So, let us look at each level in detail, beginning with the physical level.
1. Physical or Internal Level
- It is the lowest level of data abstraction that specifies how data is stored in a database.
- It defines data structures and ways for accessing data in a database.
- It is extremely complex to grasp and so kept hidden from the user.
- The database administrator determines how and where to store data in the database.
- The physical level deals with actual storage features such as data arrangement, disk space allocation, and data access techniques.
2. Logical or Conceptual Level
- It is an intermediate level located next to the physical level.
- It defines the data in the database and the relationships between them.
- It is less complicated than the physical level.
- Programmers often work at this level, where the structure of tables, relationships, and restrictions are determined based on the data.
3. View or External Level
- It represents the highest level of abstraction.
- There are various layers of views, and each view only defines a portion of the overall data requested by the user.
- This level defines many views of the same database to simulate the view for the user.
- This is the greatest level and the most easily understood by the user.
Advantages of Data Abstraction in DBMS
1. Simplifies database use
- It hides the complex details of how data is stored and managed, making it easier for users to work with databases.
- Users only interact with relevant data without needing to understand the technicalities of its storage.
2. Enhances security
- It ensures that users have access only to the necessary data while sensitive information, such as internal storage and management, is hidden.
- This minimizes unauthorized access to critical data.
3. Improves flexibility
- It allows changes in the internal storage structure without affecting how users or applications interact with the data.
- For example, the physical storage method can be optimized without requiring changes in queries or reports.
4. Reduces complexity
- It makes it easier for non-technical users to retrieve and manipulate data, as they do not need to worry about how the data is stored or organized at the physical level.
- This simplifies database operations for both users and developers.
5. Supports data independence
- It ensures that changes made at the physical level (e.g., optimizing storage or changing data formats) do not impact the logical or external levels.
- This allows database administrators to make improvements without disrupting users or applications.
How Data Abstraction Works in DBMS
- Data abstraction in DBMS works by segregating the system into three layers: the View Level, Logical Level, and Physical Level.
- At the View Level, users interact with the data through customized views, focusing on what is relevant to them.
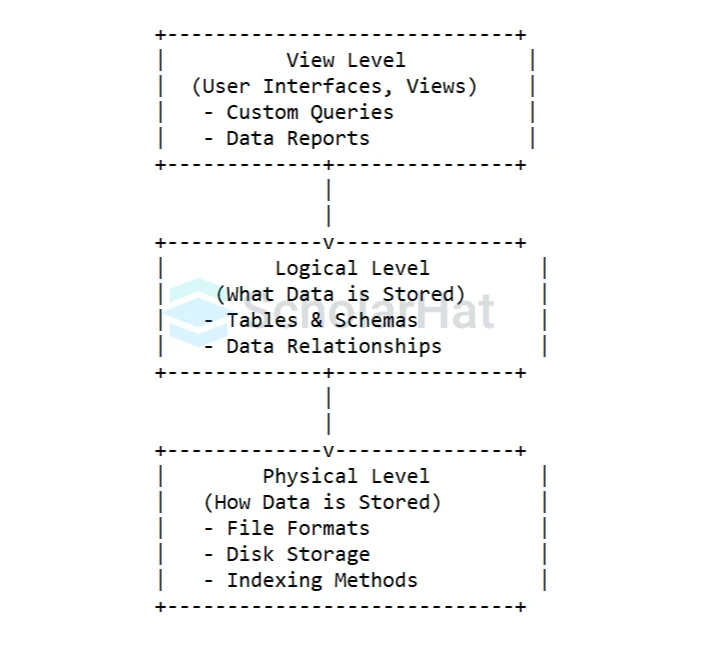
- The Logical Level defines what data is stored and how it is related without exposing the underlying storage methods.
- The Physical Level manages how data is actually stored on disk, including details like file formats and indexing.
- This separation ensures users and applications only deal with necessary details, while the DBMS handles the complexity of data storage and organization behind the scenes.
Key Differences Between Data Abstraction and Data Hiding
| Aspect | Data Abstraction | Data Hiding |
| Purpose | Simplifies interactions with complex systems by hiding unnecessary details. | Protects data by concealing implementation details and restricting access. |
| Focus | Provides a simplified view of data for easier user interaction. | Prevents unauthorized access and modification of data. |
| Scope | It involves multiple levels (physical, logical, and view) to manage complexity. | Generally applies at the level of individual objects or components. |
| Implementation | It is achieved through different layers of data abstraction (e.g., view, logical, physical). | Implemented using access control mechanisms (e.g., private, protected, public in OOP). |
| Example | Database systems abstract data storage details from users. | Encapsulation in programming where internal data of an object is hidden from outside access. |
| Visibility | Users see only the relevant data and are unaware of underlying complexities. | Internal data or methods are hidden from other parts of the program to protect integrity. |
Summary
Data abstraction in DBMS simplifies interaction with complex databases by disguising the specifics of data storage and structure at three levels: physical, logical, and view. It enables users to interact with relevant data without knowing its underlying intricacies, improves security by masking critical information, and promotes data independence by allowing changes to one level without affecting others. This abstraction allows consumers to engage with the system in a more intuitive manner while the DBMS handles the technical details. To implement your understanding, you can consider taking our SQL Server Course and MongoDB Course.
| Interview / Exam Preparation |
| DBMS Interview Questions For Freshers |
| Top 50 DBMS Viva Questions and Answers |
FAQs
The goal of data abstraction in DBMS is to make user interactions easier by hiding the complicated aspects of data storage and management. It enables people to interact with data via simplified views, while the system handles the underlying complexity, making database processes more intuitive and manageable.
Data abstraction is accomplished by classifying the database system into three levels: view, logical, and physical. Each level covers certain features from the level above it, letting people engage with a simplified version of the data while the system handles the complexities of data storage and management.
Data abstraction improves data security by obscuring sensitive information about data storage and management from users. It restricts user access to essential information while preventing unauthorized exposure of internal database architecture and sensitive data.
Common issues in creating data abstraction are:
- Performance Overheads: Abstraction layers can cause performance concerns because of the extra processing necessary to map across levels.
- Complex Design: Creating and maintaining several abstraction layers can be difficult and necessitates careful planning to ensure consistency and efficiency.
- Increased Resource Usage: Abstraction can result in higher memory and computing resource utilization as more layers of processing are involved.
- Compatibility Issues: Making sure that modifications at one level do not disturb other levels or existing applications can be difficult, especially in big systems.
Data abstraction and data hiding differ in the following ways:
- Purpose: Data abstraction simplifies interactions with complicated systems by hiding superfluous details at various levels, whereas data hiding focuses on data security by concealing implementation details and limiting access.
- Scope: Data abstraction manages complexity across various layers (view, logical, and physical), whereas data hiding often applies to particular objects or components to assure security and integrity.
- Focus: Data abstraction gives users a simpler representation of the data, whereas data hiding prevents illegal access and change by obscuring internal workings.
Take our Dbms skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.