


03
AprTop AI Interview Questions and Answers for Freshers and Experts
23 Aug 2025
Beginner
2.47K Views
42 min read

Learn with an interactive course and practical hands-on labs
Free AI-900 Course
AI Interview Questions are crucial if you’re preparing for roles in machine learning, data science, or artificial intelligence. Employers often ask about supervised vs. unsupervised learning, neural networks, deep learning, NLP, AI algorithms, and model evaluation techniques. You should also be ready for practical coding challenges and real-world AI problem-solving scenarios.
In this Artificial Intelligence Tutorial, I’ll cover the most common AI interview questions, their answers, and key concepts you need to master. You can also kickstart your AI journey with the Free Azure AI-900 Certification Course to strengthen your basics and boost your confidence for interviews.
Artificial Intelligence Interview Questions for Freshers
Here are some common Artificial Intelligence interview questions, along with detailed answers to help you ace your interview. These questions cover fundamental concepts and are tailored for freshers.
Q1. What is Artificial Intelligence (AI)?
Artificial Intelligence (AI) refers to the simulation of human intelligence in machines that are programmed to think, learn, and make decisions like humans. It involves creating algorithms and systems that can perform tasks such as problem-solving, speech recognition, planning, and more.
Q2. What are the types of Artificial Intelligence?
There are seven main types of Artificial Intelligence:
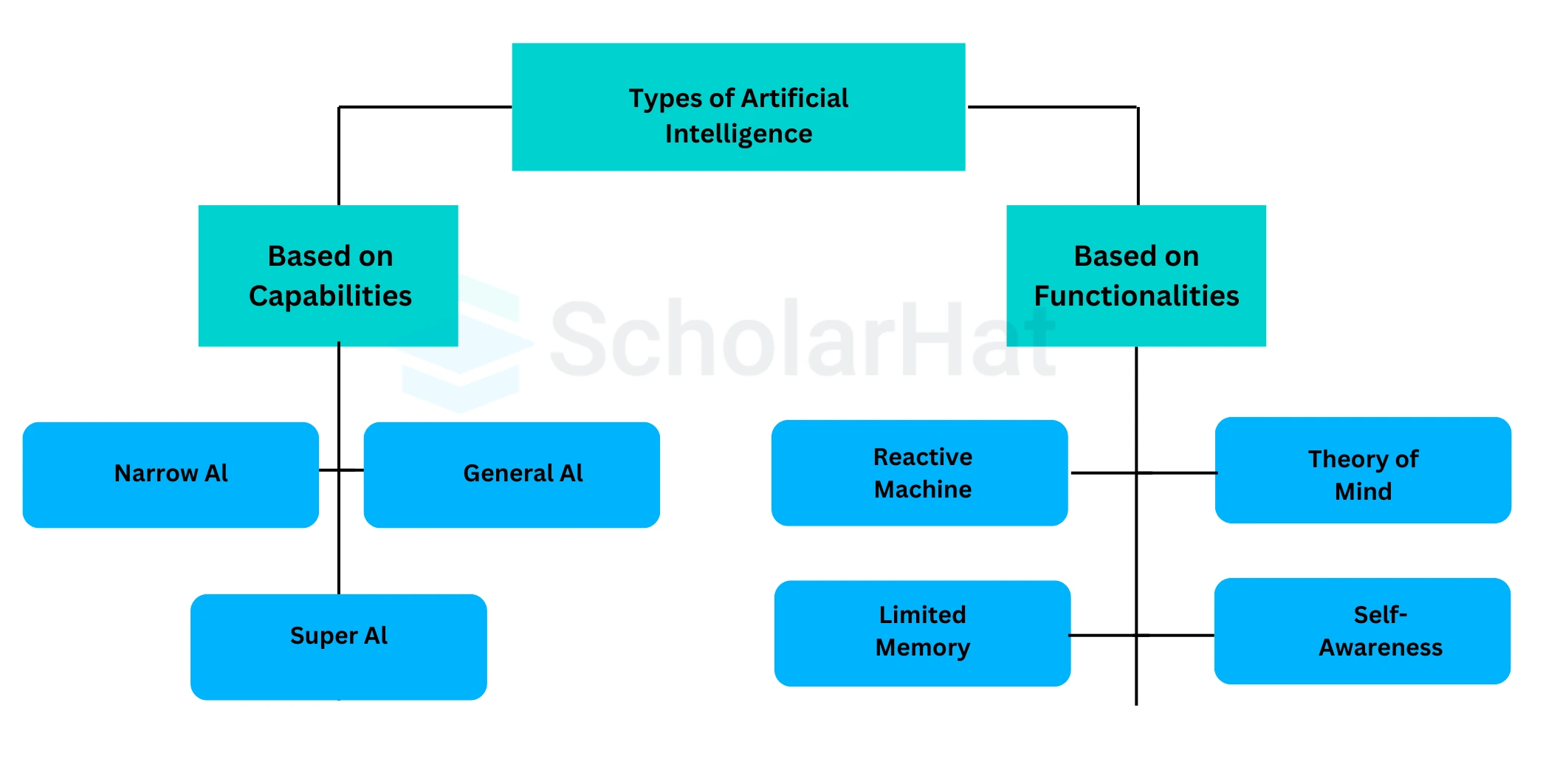
- Narrow AI (Weak AI) – These AI systems are designed to carry out specific tasks and cannot go beyond their programming. Examples include Apple’s Siri and IBM’s Watson.
- General AI – This type of AI aims to perform any intellectual task just like a human. Currently, no such AI exists, but researchers are working on developing systems that can match human intelligence.
- Super AI – This is a hypothetical AI that would surpass human intelligence and outperform humans in every way. It remains a concept for now.
- Reactive Machines – These AI models respond to situations in the best possible way based on predefined rules. They do not store past experiences. Examples include IBM’s Deep Blue and Google’s AlphaGo.
- Limited Memory AI – These machines can store and use past data for a short period. For instance, self-driving cars temporarily retain details about nearby vehicles, speed limits, and road conditions.
- Theory of Mind AI – This is a theoretical concept where AI could understand human emotions, thoughts, and social interactions, making communication more human-like.
- Self-Aware AI – This is considered the future of AI, where machines might develop consciousness, emotions, and an awareness of their own existence.
| Read More: Will Generative AI Replace Software Developers? |
Q3. What are the common algorithms used in Machine Learning?
Some common algorithms include:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- K-Means Clustering
Q4. What is the importance of data preprocessing in Machine Learning?
Datapreprocessingisessential in Machine Learning because raw data often contains missing values, noise, and inconsistencies. It helps clean, normalize, and transform data into a structured format, improving model accuracy and efficiency. Without proper preprocessing, the model may learn incorrect patterns, leading to poor performance.
Q5. What are the different types of Machine Learning?

There are three main types of machine learning:
- Supervised Learning: The model is trained on labeled data.
- Unsupervised Learning: The model is trained on unlabeled data to find patterns.
- Reinforcement Learning: The model learns by interacting with an environment and receiving rewards or penalties.
Q6. What is the Turing Test?
The Turing Test, proposed by Alan Turing in 1950, evaluates a machine's ability to exhibit human-like intelligence. In this test, a human judge interacts with both a machine and a human through text-based communication. If the judge cannot reliably distinguish the machine from the human, the machine is considered to have passed the test, demonstrating artificial intelligence.
Q7. What is Natural Language Processing (NLP)?
Natural Language Processing (NLP)is a branch of artificial intelligence that enables machines to understand, interpret, and generate human language. It combines computational linguistics with machine learning to process text and speech. NLP is used in applications like chatbots, sentiment analysis, speech recognition, and language translation.
Q8. What are neural networks?
Neural networksare a subset of machine learning inspired by the human brain.They consist of layers of interconnected nodes (neurons) that process and learn from data. Neural networks are used for pattern recognition, image processing, speech recognition, and deep learning applications. They adapt and improve over time through training using large datasets.
Q9. What is a decision tree in machine learning?
Adecision tree-supervised machine-learning algorithmused for classification and regression tasks.It splits data into branches based on feature values, forming a tree-like structure where each node represents a decision rule. The process continues until a final decision (leaf node) is reached. Decision trees are easy to interpret and handle both numerical and categorical data.
Q10. What is overfitting in machine learning?

Overfittingoccurs when themachine learning modellearns the training data too well, capturing noise and details that do not generalize to new data.This leads to high accuracy on the training set but poor performance on unseen data. It can be prevented using techniques like cross-validation, regularization, pruning (for decision trees), and increasing training data.
| Read More: Model Selection for Machine Learning |
Q11. What is underfitting in machine learning?
Underfitting occurs when a machine learning model is too simple to capture the underlying patterns in the data, leading to poor performance on both the training and test sets. This happens when the model lacks complexity or is not trained for enough iterations. It can be avoided by using more relevant features, increasing model complexity, and training for a longer duration.
Q12. What is the difference between classification and regression?
Classification and regression are two fundamental types of supervised learning in machine learning. Classification is used when the output variable is categorical, while regression is used when the output variable is continuous.
The table below highlights the key differences between Classification and Regression:
| Aspect | Classification | Regression |
| Definition | Predicts categorical labels (e.g., Yes/No, Spam/Not Spam). | Predicts continuous values (e.g., price, temperature). |
| Output Type | Discrete classes or categories. | Continuous numerical values. |
| Algorithms Used | Logistic Regression, Decision Trees, Random Forest, SVM, Neural Networks. | Linear Regression, Polynomial Regression, Decision Trees, Random Forest, Neural Networks. |
| Evaluation Metrics | Accuracy, Precision, Recall, F1-Score, ROC-AUC. | Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R-squared. |
| Example Use Cases | Email spam detection, disease diagnosis, sentiment analysis. | House price prediction, stock price forecasting, sales prediction. |
| Read More: Regression Analysis in Data Science |
Q13. What is the difference between Artificial Intelligence, Machine Learning, and Deep Learning?

Artificial Intelligence (AI) is the broader concept of machines performing tasks intelligently. Machine Learning (ML) is a subset of AI that focuses on enabling machines to learn from data without explicit programming. Deep Learning (DL) is a subset of ML that uses neural networks with multiple layers to analyze complex data patterns.
| Feature | Artificial Intelligence (AI) | Machine Learning (ML) | Deep Learning (DL) |
| Definition | AI is a broad field that enables machines to mimic human intelligence. | ML is a subset of AI that allows machines to learn from data and improve over time. | DL is a subset of ML that uses deep neural networks to automatically learn features from data. |
| Data Requirement | It can work with structured and unstructured data but may not need large datasets. | Requires a moderate amount of data for training. | Requires massive datasets for effective learning. |
| Feature Engineering | Features can be manually designed or extracted. | Requires manual feature engineering for accuracy improvement. | Automatically learns features from raw data. |
| Computational Power | Moderate computational power is required. | Requires more power than traditional AI. | Requires high computational power (GPUs, TPUs). |
| Human Involvement | May use predefined rules or logic-based systems. | Requires human intervention to fine-tune models and select features. | Minimal human intervention is needed once trained. |
| Example Applications | Chatbots, self-driving cars, expert systems. | Spam detection, recommendation systems, fraud detection. | Image recognition, speech processing, NLP. |
| Complexity | Varies from simple rule-based to advanced models. | More complex than traditional AI but interpretable. | Highly complex, with multiple hidden layers. |
Q14. What is the purpose of the activation function in neural networks?
Theactivation functioninneural networksintroduce non-linearity into the model, allowing it to learn complex patterns and relationships in data.It helps determine whether a neuron should be activated based on its input. Common activation functions include ReLU, Sigmoid, and Tanh, each serving different purposes. Without an activation function, the neural network would behave like a linear model, limiting its ability to solve complex problems.
Q15. What is the difference between supervised and unsupervised learning?
In supervised learning, the model is trained on labeled data, while in unsupervised learning, the model works with unlabeled data to find hidden patterns.
| Feature | Supervised Learning | Unsupervised Learning |
| Definition | Supervised learning is a type of machine learning where the model is trained using labeled data. | Unsupervised learning is a type of machine learning where the model learns patterns and structures from unlabeled data. |
| Training Data | Requires labeled data, where input-output pairs are provided. | Uses unlabeled data without predefined outputs. |
| Objective | To map inputs to known outputs and minimize error. | To find hidden patterns or groupings in data. |
| Examples | Email spam detection, fraud detection, speech recognition. | Customer segmentation, anomaly detection, and market basket analysis. |
| Algorithm Types | Classification (e.g., Decision Trees, SVM) and Regression (e.g., Linear Regression, Neural Networks). | Clustering (e.g., K-Means, DBSCAN) and Association (e.g., Apriori, FP-Growth). |
| Complexity | Less complex, as the data is structured and labeled. | More complex, as the model must identify patterns without guidance. |
| Use Cases | Medical diagnosis, sentiment analysis, and stock price prediction. | Image segmentation, social network analysis, genetic clustering. |
Q16. What is reinforcement learning, and where is it used?
Reinforcementlearningisa type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties.The goal is to maximize cumulative rewards over time by choosing the best possible actions.
It is used in various fields, including robotics, game playing (e.g., AlphaGo, Chess AI), self-driving cars, finance (trading strategies), and personalized recommendations. RL is ideal for problems requiring sequential decision-making and continuous learning.
Q17. What is Deep Learning?

Deep Learning is a subset of machine learning that uses artificial neural networks with multiple layers to model and understand complex patterns in data. It is widely used in image recognition, natural language processing, and speech recognition.
Q18. How does a convolutional neural network (CNN) work?
A Convolutional Neural Network (CNN) is a type of deep learning model designed for image processing and pattern recognition. It works by using three main layers:
- Convolutional Layer – Extracts features from the input image using filters (kernels) to detect edges, textures, and patterns.
- Pooling Layer – Reduces the spatial size of feature maps, making computations efficient and reducing overfitting.
- Fully Connected Layer – Flattens the extracted features and connects them to a neural network for classification or prediction.
CNNs are widely used in image recognition, object detection, medical imaging, and autonomous vehicles due to their ability to learn spatial hierarchies.
Q19. What is backpropagation in neural networks?
Backpropagation is an optimization algorithm used in neural networks to minimize errors by adjusting the weights. It works in two steps:
- Forward Propagation – The input data passes through the network, and the output is generated.
- Backward Propagation – The error is calculated using a loss function, and gradients are computed using gradient descent to update the weights and reduce the error.
Backpropagation is essential for training deep learning models, making them more accurate by continuously refining weights through multiple iterations.
Q20. What is the purpose of cross-validation in machine learning?
Cross-validation is used to assess the performance of a machine-learning model by splitting the data into different subsets. This helps to ensure the model generalizes well to unseen data. How do you think cross-validation affects model performance?
Artificial Intelligence Interview Questions for Intermediates
Anintermediate-level AI interview, you’ll need to dive deeper into advanced concepts and practical applications. Below are some Artificial Intelligence interview questions tailored for intermediates.
Q21. What is the Chinese Room argument, and how does it challenge AI intelligence?
The Chinese Room argument, proposed by John Searle, challenges the idea that AI can truly understand language. It describes a scenario where a person inside a room follows instructions to manipulate Chinese symbols without understanding their meaning. This suggests that AI, like the person in the room, processes data syntactically but lacks real understanding or consciousness.
Q22. What is the role of activation functions in neural networks?
Activation functions play a critical role in neural networks by introducing non-linearity into the model. Without activation functions, a neural network would simply be a linear regression model incapable of learning complex patterns. Common activation functions include ReLU (Rectified Linear Unit), Sigmoid, and Tanh. These functions help the network learn and model complex relationships in the data, enabling it to perform tasks like image recognition and natural language processing.
Q23. How does deep learning differ from machine learning?
Deep Learning is a subset of Machine Learning that uses multi-layered neural networks to analyze and learn from data. While traditional machine learning algorithms require manual feature extraction, deep learning models automatically extract features from raw data. This makes deep learning particularly effective for tasks like image and speech recognition, where the data is complex and high-dimensional. In contrast, machine learning is often used for simpler tasks with structured data.
Q24. What is the difference between a classification problem and a regression problem in machine learning?
In a classification problem, the goal is to predict discrete labels or categories, such as identifying whether an email is spam or not. On the other hand, a regression problem involves predicting continuous values, such as estimating the price of a house based on its features. Classification algorithms include Logistic Regression and Decision Trees, while regression algorithms include Linear Regression and Ridge Regression.
Q25. How does reinforcement learning work? Give an example.
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives rewards for positive actions and penalties for negative ones, guiding it toward optimal behavior. For example, in training an AI to play chess, the agent receives a reward for winning and a penalty for losing. Over time, it learns strategies to maximize rewards. RL is widely used in robotics, gaming, and autonomous systems.
Q26. What are the key differences between semi-supervised and unsupervised learning?
Semi-supervised learning uses a small amount of labeled data along with a large set of unlabeled data, while unsupervised learning works only with unlabeled data. Semi-supervised learning improves accuracy by leveraging labeled data, whereas unsupervised learning focuses on finding patterns or structures without any prior labels.
Q27. What is overfitting, and how can it be prevented in machine learning?
Overfitting occurs when a model learns the training data too well, including noise and outliers, resulting in poor performance on new, unseen data. To prevent overfitting, techniques like cross-validation, regularization, and early stopping can be used. Additionally, increasing the amount of training data and simplifying the model can help reduce overfitting.
Q28. What is cross-validation in machine learning? Why is it important?
Cross-validation is a technique used to evaluate the performance of a machine-learning model by partitioning the data into multiple subsets. The model is trained on some subsets and validated on the remaining ones. This process is repeated multiple times to ensure the model's robustness. Cross-validation is important because it provides a more accurate estimate of the model's performance on unseen data, reducing the risk of overfitting.
Q29. What are the main challenges in training deep learning models?
Training deep learning models comes with several challenges, including:
- Computational Complexity: Deep learning models require significant computational resources and time to train.
- Data Requirements: These models need large amounts of labeled data to perform well.
- Overfitting: Deep learning models are prone to overfitting, especially with small datasets.
- Hyperparameter Tuning: Selecting the right hyperparameters can be time-consuming and complex.
Q30. What is the importance of feature scaling in machine learning?
Feature scaling is a crucial step in Data Processing in Machine Learning, where the range of features in a dataset is normalized or standardized. It is essential because algorithms like K-Nearest Neighbors (KNN) and Support Vector Machines (SVM) are sensitive to data scale. By applying scaling, all features contribute equally, enhancing model accuracy and improving convergence speed.
Q31. What is the role of convolutional layers in Convolutional Neural Networks (CNNs)?
Convolutional layers are the building blocks of Convolutional Neural Networks (CNNs). They apply a convolution operation to the input data, extracting features like edges, textures, and patterns. These layers use filters (kernels) to scan the input image, producing feature maps that highlight important aspects of the data. Convolutional layers are essential for tasks like image recognition and object detection.
Q32. Explain the concept of transfer learning in deep learning.
Transfer learning is a technique in deep learning where a pre-trained model is reused as the starting point for a new task. Instead of training a model from scratch, transfer learning leverages the knowledge gained from solving one problem to solve a related problem. This approach is particularly useful when working with limited data or computational resources. For example, a model trained on ImageNet can be fine-tuned for a specific image classification task.
Q33. How does a Support Vector Machine (SVM) work? What are its advantages?
A Support Vector Machine (SVM) is a supervised learning algorithm used for classification and regression tasks. It works by finding the hyperplane that best separates the data into different classes while maximizing the margin between the classes. SVMs are effective in high-dimensional spaces and are robust to overfitting. Their advantages include versatility (they can handle linear and non-linear data) and strong performance on small to medium-sized datasets.
Q34. What are generative adversarial networks (GANs)? How do they work?
Generative Adversarial Networks (GANs) are a class of deep learning models consisting of two neural networks: a generator and a discriminator. The generator creates fake data, while the discriminator evaluates whether the data is real or fake. The two networks are trained simultaneously in a competitive manner, with the generator improving its ability to create realistic data and the discriminator getting better at distinguishing real from fake. GANs are widely used for image generation, video synthesis, and data augmentation.
Q35. What is the curse of dimensionality in machine learning?
The curse of dimensionality refers to the challenges that arise when working with high-dimensional data. As the number of features increases, the volume of the data space grows exponentially, making it sparse and harder to analyze. This can lead to overfitting, increased computational complexity, and reduced model performance. Techniques like dimensionality reduction (e.g., PCA) and feature selection are often used to mitigate this issue.
Artificial Intelligence Interview Questions for Experienced
An experienced-level AI interview, you’ll need to showcase a deeper understanding of complex AI concepts and their real-world applications. Below are some Artificial Intelligence interview questions tailored for experienced professionals.
Q36. What is the Loebner Prize, and how does it relate to AI evaluation?
TheLoebner Prizewas an annual competition forartificial intelligencebased on, the Turing Test.It awarded AI systems that best mimicked human conversation. The competition evaluated chatbots on their ability to convince judges that they were human, serving as a benchmark for AI's progress in natural language understanding.
| Read More: ChatGPT vs Software Developers |
Q37. How do you choose the right machine-learning model for a given problem?
Selecting the right machine learning model requires careful consideration of several factors to ensure optimal performance.
- Nature of the Problem: Determine whether the task is classification, regression, clustering, reinforcement learning, or anomaly detection.
- Data Availability and Quality: The choice of model depends on the size, completeness, and distribution of the dataset. Large datasets with high variance might benefit from deep learning, while smaller datasets may perform well with traditional algorithms like decision trees.
- Computational Resources: Neural networks require significant computational power, while simpler models like logistic regression can be deployed on limited hardware.
- Interpretability vs. Accuracy: If interpretability is crucial (e.g., in healthcare or finance), simpler models like decision trees and logistic regression may be preferable. However, for high accuracy, complex models like deep learning can be used.
Q38. What are the advantages and disadvantages of using decision trees in machine learning?
Decision trees are widely used in machine learning due to their simplicity and interpretability. However, they have some limitations that affect their performance. Below is a comparison of the advantages and disadvantages of decision trees:
| Aspect | Advantages | Disadvantages |
| Interpretability | Easy to understand and interpret, even for non-experts. | Complex trees can become difficult to interpret. |
| Data Preprocessing | Requires little data preprocessing, as it handles missing values and outliers well. | May struggle with noisy data, leading to overfitting. |
| Computation | Computationally efficient for small to medium datasets. | Training large trees can be time-consuming and require more memory. |
| Feature Selection | Automatically selects the most important features. | It can be biased toward features with more levels (categorical variables with many categories). |
| Overfitting | Pruning techniques can help reduce overfitting. | Highly sensitive to changes in data, leading to overfitting without pruning. |
| Model Generalization | Works well for simple decision-making problems. | Performs poorly on complex datasets without ensemble methods (e.g., Random Forest). |
| Scalability | It can scale well with proper tuning and pruning. | It is not ideal for very large datasets due to exponential tree growth. |
Q39. Explain the concept of deep reinforcement learning and its applications.
Deep reinforcement learning (DRL) is an advanced AI technique that combines deep learning with reinforcement learning to enable agents to learn optimal actions through trial and error.
- Learning Process: An agent interacts with an environment, takes actions, and receives rewards or penalties based on outcomes. Over time, the agent refines its strategy to maximize cumulative rewards.
- Use of Neural Networks: DRL employs deep neural networks to approximate value functions or policies, enabling it to handle high-dimensional and complex environments.
- Applications: DRL is widely used in robotics (autonomous control), gaming (AlphaGo, Dota 2 AI), finance (automated trading), and autonomous driving (self-driving cars learning optimal driving strategies).
Q40. What are generative adversarial networks (GANs), and how do they work?
Generative Adversarial Networks (GANs) are deep learning architectures designed to generate realistic synthetic data by using two neural networks in competition.
- Generator: Creates fake samples that mimic real data.
- Discriminator: Evaluates samples and distinguishes between real and generated ones.
- Through an iterative training process, the generator improves its ability to create realistic outputs, making GANs powerful for applications like image generation, style transfer, deepfake creation, and data augmentation.
Q41. What are word embeddings in NLP, and why are they important?
Word embeddings are numerical vector representations of words that capture their meanings based on context and relationships with other words in a given corpus. They help NLP models understand semantic similarities, enabling better performance in tasks like machine translation, sentiment analysis, and text classification. Unlike traditional one-hot encoding, word embeddings provide dense, meaningful representations that improve accuracy and efficiency. Popular techniques include Word2Vec, GloVe, and FastText.
Q42. Explain the concept of backpropagation in neural networks.
Backpropagation is an optimization algorithm used to train neural networks by adjusting weights to minimize the error between predicted and actual outputs.
- Process: Involves forward propagation (computing predictions), calculating error using a loss function, and backward propagation of the error to update weights.
- Gradient Descent: Uses techniques like Stochastic Gradient Descent (SGD) to optimize weight updates.
- Importance: Backpropagation enables deep neural networks to learn complex patterns from data, making it foundational for deep learning.
Q43. How would you handle missing data in a machine-learning project?
Handling missing data is crucial for ensuring model accuracy and reliability. Different techniques can be applied depending on the nature and amount of missing data.
- Imputation: Replace missing values with statistical measures such as the mean, median, or mode of the respective column. This is useful for numerical data.
- Deletion: If missing data is minimal, you can remove rows or columns with missing values. However, excessive deletion can lead to data loss and biased models.
- Prediction-Based Filling: Use machine learning algorithms (e.g., KNN imputation or regression) to predict and fill missing values.
- Indicator Variables: Introduce a separate column indicating whether a value was missing. This helps the model recognize missing patterns.
Choosing the right approach depends on the dataset and the impact of missing values on model performance.
Q44. What is feature engineering, and why is it important in machine learning?
Feature engineering is the process of transforming raw data into meaningful features that improve model performance.
- Feature Selection: Identifying and retaining the most relevant features while discarding irrelevant ones to prevent overfitting.
- Feature Transformation: Applying techniques like normalization, standardization, or encoding categorical variables to make data suitable for modeling.
- Feature Extraction: Using techniques like Principal Component Analysis (PCA) or deep learning embeddings to reduce dimensionality.
- Feature Creation: Generating new features based on existing ones (e.g., creating an "age group" feature from raw age data).
Good feature engineering enhances model accuracy, interpretability, and efficiency, often having a more significant impact than choosing a complex machine learning algorithm.
Q45. Explain the concept of hyperparameter tuning and its importance in machine learning models.
Hyperparameter tuning is the process of selecting the best set of hyperparameters that optimize machine learning model performance.
- Hyperparameters vs. Parameters: Hyperparameters (e.g., learning rate, number of layers) are set before training, while parameters (e.g., weights) are learned during training.
- Manual Search: Experiment with different hyperparameter values manually to determine the best settings.
- Grid Search: Systematically testing all possible hyperparameter combinations and selecting the best-performing one.
- Random Search: Randomly selecting hyperparameter values and evaluating their performance.
- Bayesian Optimization: Using probabilistic models to efficiently explore the hyperparameter space and find optimal settings.
Proper hyperparameter tuning prevents underfitting or overfitting and ensures the best model accuracy.
Q46. What is the purpose of dropout in deep learning models, and how does it work?
Dropout is a regularization technique used in deep learning to prevent overfitting by randomly dropping neurons during training.
- How It Works: During each training iteration, a fraction of neurons is randomly deactivated, forcing the neural network to learn robust features and preventing reliance on specific neurons.
- Dropout Rate: The probability of dropping a neuron is typically set between 20-50%, depending on the complexity of the model.
- Effect on Model Performance: Helps generalization, ensuring the model performs well on unseen data.
- Implementation: Commonly used in deep neural networks (DNNs) and convolutional neural networks (CNNs) by adding a dropout layer after dense layers.
Dropout acts as a form of ensemble learning, as it simulates multiple models by training with different subsets of neurons.
Q47. What are ensemble learning techniques, and how do they improve model performance?
Ensemble learning combines multiple machine learning models to improve prediction accuracy and robustness.
- Bagging (Bootstrap Aggregating): Uses multiple models trained on different subsets of data and combines their predictions (e.g., Random Forest).
- Boosting: Sequentially trains weak models, giving more focus to misclassified instances, ultimately improving performance (e.g., AdaBoost, Gradient Boosting, XGBoost).
- Stacking: Combines multiple models and uses another model to learn how to best combine their outputs.
- Voting: Uses multiple models and selects the most common (classification) or averaged (regression) prediction.
Ensemble techniques reduce variance and bias, leading to higher model accuracy and stability.
Q48. How do you deal with class imbalance in classification problems?
Class imbalance occurs when one class has significantly more samples than another, leading to biased model predictions.
- Resampling Techniques: Oversampling (e.g., SMOTE) increases minority class samples, while undersampling reduces majority class samples.
- Weighted Loss Function: Assigning higher weights to minority class instances to balance the training process.
- Data Augmentation: Creating synthetic samples using techniques like rotation, flipping, or GANs.
Proper handling of class imbalance ensures fair and accurate model predictions.
Q49. How does a recurrent neural network (RNN) differ from a convolutional neural network (CNN)?
A Recurrent Neural Network (RNN) and a Convolutional Neural Network (CNN) serve different purposes in deep learning. RNNs are designed for sequential data, where past inputs influence future predictions, making them suitable for tasks like speech recognition and language modeling. CNNs, on the other hand, are optimized for spatial data, primarily images, using convolutional layers to detect patterns like edges and textures. While RNNs handle sequential dependencies, CNNs excel in feature extraction from images.- Data Type: RNNs work with sequential data (e.g., text, speech), whereas CNNs are designed for spatial data (e.g., images, videos).
- Architecture: RNNs have recurrent connections, allowing information to persist across time steps, while CNNs use convolutional layers to detect spatial features.
- Use Cases: RNNs are ideal for tasks like speech recognition, language modeling, and time-series forecasting. CNNs excel in image classification, object detection, and facial recognition.
- Memory Handling: RNNs can remember past inputs, making them useful for context-based predictions. CNNs process information hierarchically, focusing on spatial relationships.
Q50. What is one-shot learning, and how does it differ from traditional deep learning approaches?
One-shot learning is a machine learning approach where a model learns from just a few or even a single example per class rather than requiring a large dataset. It is commonly used in facial recognition and signature verification, where gathering extensive data for each subject is impractical. This technique relies on methods like Siamese Networks and Memory-Augmented Networks, enabling models to generalize from minimal data.
The table below highlights the key differences between One-Shot Learning and Traditional Deep Learning Approaches:
| Aspect | One-Shot Learning | Traditional Deep Learning |
| Training Data | Requires very few examples per class. | Requires large labeled datasets. |
| Learning Method | Uses metric learning, memory networks, or transfer learning. | Uses backpropagation and gradient descent for optimization. |
| Generalization | Can generalize well with minimal training data. | Needs extensive training to generalize effectively. |
| Computation | Computationally efficient due to less training data. | Computationally intensive, requiring high resources. |
| Use Cases | Facial recognition, signature verification, medical diagnosis. | Image classification, speech recognition, autonomous driving. |
| Read More: Career Options in Generative AI |
Summary
Mastering AI is crucial if you want to stand out in today's competitive job market. From this deep dive into the top AI interview questions and answers, it’s clear that having a solid grasp of key concepts is a must for success in AI interviews. But why stop there? Why not take your knowledge to the next level?
Consider enrolling in Scholarhat's Azure AI Engineer course and Azure AI Foundry training to boost your skills. This course offers hands-on learning, expert guidance, and valuable insights into the latest advancements in AI technology.
Test Your Knowledge of AI!
Q 1: What is Artificial Intelligence?
- (a) The ability of a machine to perform tasks that require human intelligence
- (b) A type of machine learning
- (c) A method of data analysis
- (d) A computer programming language
Q 2: Which of the following is an example of machine learning?
- (a) A program that calculates the sum of numbers
- (b) A computer vision system that detects objects in images
- (c) A text editor
- (d) A search engine
Q 3: What is supervised learning?
- (a) A type of learning where the model is given input-output pairs to learn from
- (b) A type of learning where the model tries to find patterns without any labeled data
- (c) A form of reinforcement learning
- (d) A method where the machine simulates human thinking
Q 4: Which algorithm is commonly used for classification tasks in machine learning?
- (a) Linear Regression
- (b) Decision Trees
- (c) K-Means Clustering
- (d) K-Nearest Neighbors
Q 5: What is the purpose of a loss function in machine learning?
- (a) To optimize the model by adjusting the parameters
- (b) To measure the error between predicted and actual values
- (c) To divide the dataset into training and testing sets
- (d) To visualize the results of the model
FAQs
The best AI for interview questions depends on your needs. ChatGPT (like this one) provides detailed, conversational responses. Google Gemini offers up-to-date insights, while Claude AI focuses on in-depth reasoning. For coding interviews, Codex or Copilot can assist with AI-driven programming solutions.
One of the hardest questions in AI is: "Can AI achieve true consciousness or self-awareness?" This question challenges our understanding of intelligence, cognition, and whether machines can develop emotions, self-awareness, or human-like reasoning beyond programmed responses.
The main types of AI are:
- Narrow AI (Weak AI): Designed for specific tasks like chatbots and recommendation systems.
- General AI (Strong AI): Hypothetical AI that can perform any intellectual task like a human.
- Super AI: A theoretical AI surpassing human intelligence, capable of independent thinking and innovation.
Take our Generativeai skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.