






13
MarReinforcement Learning
27 Jul 2025
Beginner
4.43K Views
18 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Introduction
A well-known subfield of machine learning called reinforcement learning (RL) aims to make it possible for an agent to learn from its interactions with the environment and make decisions. RL operates in circumstances where the agent learns via trial and error and receives feedback in the form of rewards or penalties for its behaviour, in contrast to other machine learning approaches that rely on labelled data.
In real-world simulations, an agent gradually learns to maximise its cumulative reward by identifying the best course of action. This policy establishes the actions the agent ought to do in various environmental conditions. Finding the policy that maximises the return, sometimes referred to as the long-term expected reward, is the main objective of RL.
There are three essential parts to the RL framework: the agent, the environment, and their interactions. The environment responds by changing into a new state and giving feedback in the form of incentives or penalties after the agent conducts actions based on its present state. The agent's goal is to discover a policy that enables it to take the best possible actions in order to maximize cumulative reward.
The idea of a trade-off between exploration and exploitation is one of the fundamental ideas in RL. Early in the learning process, the agent experiments in the environment to learn about the effects of various behaviors. As it gains more knowledge, the agent uses that knowledge to improve judgments and increase rewards.
RL algorithms use a variety of methods to efficiently learn policies. One well-liked method is known as "Q-Learning," which estimates the predicted cumulative reward for performing a specific action in a specific state using a value function. The agent updates its policy and improves its decisions over time using this value function.
Deep Q-Networks (DQN), which blends RL with deep neural networks, is another popular RL technique. DQN uses deep learning to handle high-dimensional state spaces and estimate the value function. It has made tremendous progress in activities like operating robotic systems and playing video games.
Robotics, autonomous vehicles, engines for recommendation, finance, healthcare, and other fields are just a few of the fields where RL is used. Agents have been trained to play hard video games, save energy use, find their way around dangerous locations, and even manage intricate industrial operations.
Reinforcement machine learning
Reinforcement machine learning is concerned with teaching agents how to choose actions that would maximize a cumulative reward. It draws inspiration from how both people and animals pick up new skills through mistakes when interacting with their environment.
In real life, an agent learns to move across space by acting, watching the ensuing state changes, and getting feedback in the form of incentives or penalties. The agent's goal is to discover a policy—a mapping of states to actions—that maximizes the projected long-term benefit.
Numerous fields, including robotics, gaming, autonomous systems, systems for a recommendation, healthcare, finance, and more have effectively used reinforcement learning. It facilitates autonomous development and adaptive behavior by enabling agents to learn and make decisions in constantly changing and uncertain settings.
Types of reinforcement learning
Reinforcement in machine learning can refer to several signals or forms of feedback utilized in Reinforcement Learning (RL). Here are three essential types of reinforcement learning that are frequently applied in RL:
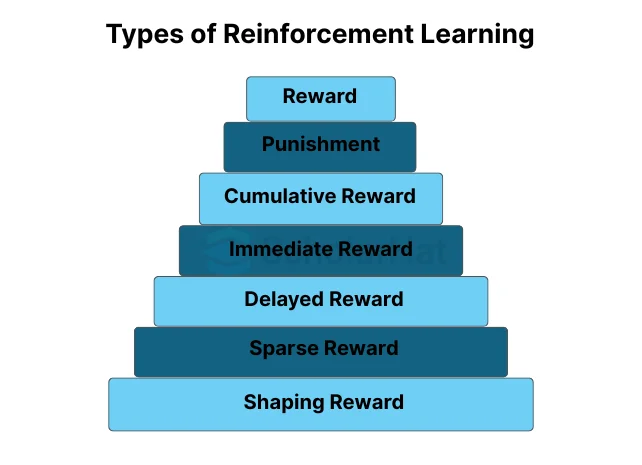
Reward
In real life, rewards are the main way to reinforce behavior. They give the agent feedback based on its behaviors and indicate if those actions were desirable. Rewards can be scalar values that are either positive, negative, or neutral. Maximizing the agent's cumulative reward over time is its objective.
Punishment
When an agent engages in undesired acts or behaviors, they are punished. The agent is deterred from engaging in certain behaviors or approaching particular environmental conditions by punishments. They are employed to mold the agent's behavior by punishing bad decisions.
Cumulative Reward
A cumulative reward is the total of all rewards received by an agent over the course of a series of activities. It is also referred to as the return or the entire reward. The goal of RL algorithms is to learn policies that maximize cumulative reward while taking into account both the immediate and long-term effects of decisions.
Immediate Reward
Immediate benefits are those that one receives right away for adopting an environmental activity. They give the agent quick feedback and are essential in directing its decision-making process.
Delayed Reward
Delayed rewards are those that are felt over a longer period of time or following several activities. RL algorithms frequently deal with delayed incentives, where the agent needs to learn to link past actions with future rewards.
Sparse Reward
Rewards that are rarely offered or that are only granted when certain requirements or objectives are accomplished are referred to as sparse rewards. Since the agent must search the environment for rewarding states or actions, sparse reward settings might make RL problems more difficult.
Shaping Reward
Shaping rewards are extra rewards that are given to help the agent's learning process. They may be created to give the agent intermediate feedback, accelerating learning or promoting desired behaviors.
Elements of Reinforcement Learning
The structure and dynamics of Reinforcement Learning (RL) in machine learning are defined by a number of essential components. The key elements of reinforcement learning are as follows:
- Agent: An agent is a learner or decision-maker who engages in environment-based interactions. It observes how the environment is right now, chooses actions in accordance with its policy, and aims to maximize the cumulative reward. Any entity that is able to act can be the agent, including software programs, robots, and other mechanical devices.
- Environment: The external system or environment in which the agent functions is referred to as the environment. It is made up of states, which stand in for various arrangements or circumstances, and the rules that control how states change in response to an agent's activities. The environment may be stochastic, where activities may result in a variety of unpredictable consequences, or deterministic, where actions have predictable results.
- State: The state depicts how the environment is currently set up or situated. It includes all pertinent data required for the agent to make decisions. The qualities or factors that affect the agent's behavior or the dynamics of the environment can be used to describe the state.
- Action: The decisions an agent makes in order to change the environment are called actions. The range of options is determined by the particular RL issue. Choosing from a list of predetermined possibilities is an example of a discrete action. Choosing a value from a continuous range is an example of continuous action.
- Reward: Rewards let the agent know whether or not its activities were worthwhile. The immediate effects of an action in a certain state are often quantified by scalar numbers. Rewards may be neutral (having no influence), negative (discouraging undesirable activities), or positive (encouraging desired actions). Maximizing the agent's cumulative reward over time is its objective.
- Policy: The agent's policy is the method or set of rules it uses to choose how to act in response to the observed states. It facilitates the agent's decision-making by mapping states to actions. The policy may be deterministic (always choosing the same course of action for a particular state) or stochastic (choosing courses of action based on probabilities).
- Value Function: This function calculates the predicted total gain or value of existing in a certain condition or performing a particular activity in a certain state. It measures how beneficial or useful a condition or activity is in terms of potential benefits. Value functions are essential for directing the agent's learning and decision-making processes.
- Exploration and exploitation: The agent's strategy of attempting various activities to learn more about the environment and uncover potentially lucrative states is referred to as exploration. Contrarily, exploitation entails using the agent's acquired information to guide decisions that maximize short-term gains in light of its existing knowledge.
Application of Reinforcement Learning
In several machine learning fields, reinforcement learning (RL) has found uses. application of reinforcement learning, such as:
- Game Playing: RL has been successfully used in circumstances including gameplay, with outstanding outcomes. For instance, DeepMind's AlphaGo & AlphaZero used RL approaches to outperform humans in complex games like Go, chess, & shogi. By competing with themselves or learning from human experts, RL enables agents to develop the best possible strategy.
- Robotics: To help robots learn to understand and respond to their environments, RL is widely employed in robotics. Robots may be taught to carry out difficult tasks including gripping objects, moving around, navigating, and manipulating things using RL algorithms. By making mistakes and learning from them, robots can improve their strategies by interacting with the real environment.
- Autonomous cars: The development of autonomous cars depends heavily on RL. Vehicles can be taught to make judgments in real-time using RL algorithms, including adaptive cruise control, route planning, and lane change. By interacting with the environment and taking into account variables like traffic conditions, safety, & fuel efficiency, RL enables vehicles to learn the best driving practices.
- Recommender Systems: RL has been used in recommender systems, which aim to recommend products that are pertinent to users. Based on observed user input and interactions with the system, RL algorithms are able to recommend products by maximizing the user's long-term pleasure or engagement.
- Finance: RL has found use in portfolio management and financial trading. Based on market circumstances, historical data, and planned financial objectives, RL algorithms can develop trading policies to optimize investment decisions. RL can manage the financial markets' dynamism and modify plans in response to shifting circumstances.
- Healthcare: Applications for RL in healthcare are being investigated more and more. Treatment planning, personalized medicine, and resource distribution in healthcare systems can all be optimized using it. RL can assist in creating the best plans for managing diseases, administering medications, scheduling patients, and making clinical decisions.
- Control Systems: To optimize the behavior of complex systems, RL is used in control systems. To monitor and control processes in industries like manufacturing, energy management, robotics, & industrial automation, RL algorithms can learn control strategies. To boost system effectiveness and efficiency, RL can optimize variables and processes.
- Natural Language Processing: RL is used for problems involving the processing of natural languages, such as machine translation and dialogue systems. Agents can be taught to have conversations, produce responses, and improve the conversation flow depending on user feedback using RL approaches.
How does Reinforcement Learning Work?
Reinforcement Learning (RL) is a type of machine learning that involves an agent interacting with its environment, learning from its mistakes, and then improving its decision-making procedures. Here is a general description of how RL functions:
- Identify the Problem: The first stage in RL is defining the problem and all of its elements. This entails describing the agent's environment, states, actions, & ultimate goal or objective.
- Agent-Environment Interaction: The RL agent engages in sequential interactions with its surroundings. The agent examines the status of the environment at each time step, chooses an action in accordance with its policy, and then performs that action.
- State Transitions & Rewards: When an action is taken, the environment changes depending on the action taken by the agent. The environment provides the agent with feedback in the form of a reward, which measures the action's desirability or quality in that state.
- Learning from Experience: By frequently interacting with the environment, the agent gains experience. It keeps track of the observed states, behaviors, rewards, and state transitions that they led to. The agent then uses this experience to learn from it and develop its decision-making skills.
- Policy Learning: The agent's goal is to identify the best possible policy—a mapping from states to deeds—that maximizes the cumulative long-term benefit. RL algorithms employ a variety of methods to efficiently learn policies. They can apply policy optimization techniques, which directly improve the policy, or value functions, which calculate the predicted cumulative reward for doing a particular action in a specific state.
- Exploration & exploitation: RL agents must decide between the two. In the beginning, the agent performs a variety of activities in order to investigate the effects of its decisions. As the agent gains information, it begins to use it to maximize rewards and improve decisions.
- Policy Evaluation & Improvement: Based on the observed rewards & state changes, RL algorithms modify the agent's policy. The value function may be estimated as part of this update, or the policy parameters may be changed directly. The objective is to continuously improve the policy in order to maximize the expected cumulative reward and produce improved performance.
- Iteration and Convergence: The RL method is iterative. The agent keeps interacting with its surroundings, learning from them, updating its policies, and honing its decision-making. An agent gradually converges on an ideal policy that maximizes the cumulative reward through this iterative procedure.
- Evaluation and Testing: The effectiveness of the agent is assessed using hypothetical or real-world data after the RL algorithm has converged or established a desirable policy. This evaluation aids in determining the efficacy of the learned policy and, if necessary, allows for adjustments.
Upper Confidence Bound
For managing the exploration-exploitation trade-off, Reinforcement Learning (RL) frequently uses the Upper Confidence Bound (UCB) algorithm. It is intended to strike a balance between investigating unexplored actions and taking advantage of those that, based on the facts at hand, seems to be the best. In multi-armed bandit issues, where an agent must choose actions from a list of possibilities while attempting to maximize the cumulative payoff, the UCB algorithm is frequently utilized.
The UCB algorithm offers a methodical strategy to investigate several courses of action while favoring those with greater estimated values & uncertain results. The system learns to prioritize activities that give higher rewards by gradually changing the estimated amounts based on the rewards obtained, and it converges into an ideal policy.
Numerous applications of the UCB algorithm have been developed, including internet advertising, recommendation systems, clinical trials, and resource allocation issues. It is a useful tool for tackling the exploration-exploitation trade-off in RL due to its simplicity and effectiveness. The UCB algorithm operates as follows:
- Initialization: Give the UCB algorithm a start by estimating the reward or value of each action. Setting the initial estimations to zero or applying another heuristic could accomplish this.
- Exploration-Exploitation Trade-Off: To balance exploration and exploitation, the UCB algorithm assesses the upper confidence bound for each action at each time step. Based on the projected value of the action and the related uncertainty, the upper confidence bound is computed. The agent is encouraged to choose options with high estimated values but high levels of uncertainty.
- Action Selection: The greatest upper confidence bound action is chosen by the UCB algorithm. By selecting actions with high estimated values with substantial uncertainty, the system encourages the exploration of potentially lucrative behaviors.
- Action Execution & Reward: The chosen action is carried out in the environment, and depending on how it turns out, the agent is rewarded or given feedback. The estimated value of the selected action is then updated using the reward.
- Value Update: After obtaining the reward, a suitable update rule is used to update the projected value of the selected action. Depending on the precise version of the UCB algorithm being utilized, this update rule may change. Common strategies include averaging techniques or incremental update rules.
- Repetition: For succeeding time steps, repeat steps 2 through 5. The estimated values are more precise and the uncertainty goes down as the agent acquires more data and rewards. Over time, this leads to a more precise balance between exploration and exploitation.
Thompson Sampling
For the purpose of addressing the trade-off between exploration and exploitation, Thompson Sampling can also be used in the context of reinforcement learning (RL). Thompson Sampling is frequently employed in real-world situations where the agent's objective is to interact with the environment and reap rewards in order to learn the best possible policy. In real life, Thompson Sampling can be applied as follows:
- Initialization: Establish prior distributions for the variables or value functions connected to each action or state-activity pair to begin the RL algorithm. These priors represent the initial assumptions on the values of the actions or state-action pairs.
- Action Selection: Based on the measured rewards and prior distributions, Thompson Sampling selects a set of values for parameters from the posterior distribution of every action or state-action pair at each time step. The parameters that were sampled indicate several potential action or state-action consequences.
- Policy Evaluation: The RL algorithm evaluates the value or predicted cumulative reward associated with each sampled set of parameters for each action or state-activity pair. Value functions, like the Q-value or state-value functions, are often the foundation of this evaluation.
- Thompson Sampling chooses the action or state-action pair based on the sampled parameter sets that have the highest expected value. Accordingly, the algorithm selects the action or state-action pair that, given the available information and uncertainty, is most likely to result in optimal rewards.
- Action Execution & Reward: The chosen action is carried out in the environment, and depending on how it turns out, the agent is rewarded or given feedback.
- Bayesian Update: Based on Bayesian inference, Thompson Sampling updates the posterior distributions of the parameters for the action or state-action pair after receiving the reward. The prior distributions and the observed rewards are combined to update the posterior distributions.
- Policy Improvement: Based on observed rewards and revised posterior distributions, the RL algorithm modifies the policy. Different methods, such as policy gradients or value iteration methods, can be used to update the system.
- Repetition: For succeeding time steps, repeat steps 2 through 7. The posterior distributions reflect the agent's updated ideas about the worth of the actions or state-action pairings when more rewards are gathered and Bayesian updates are carried out.
Summary
Reinforcement machine learning is concerned with giving an agent the ability to learn from and respond to its surroundings. By relying on trial-and-error learning, where the agent is given feedback in the form of rewards or penalties for its behaviors, RL differentiates from other machine learning methodologies. The goal of the agent is to discover a course of action that maximizes the cumulative reward over time.
The agent, the environment, and their interaction make up the three core parts of the RL architecture. The environment responds by changing into a new state and giving feedback in the form of rewards or penalties after the agent conducts actions based on its present state. In order to maximize the cumulative reward, the agent seeks to learn a policy that enables it to make the best judgments possible.
The exploration-exploitation trade-off is a key idea in RL. The agent initially investigates its surroundings to gather data, and then it uses this information to improve its decision-making. To develop efficient policies, RL algorithms use a variety of methods, including Q-learning & Deep Q-Networks (DQN). While DQN blends RL with deep neural networks to handle high-dimensional state spaces, Q-learning uses a value function to predict the expected cumulative reward for actions in various states.
Robotics, autonomous vehicles, recommendation systems, banking, and healthcare are just a few of the industries where RL is used. Agents have been trained to play hard games, reduce energy use, navigate hazardous locations, and manage industrial processes.
A well-liked algorithm in RL that addresses the exploration-exploitation trade-off is Thompson Sampling. Selecting parameter values from posterior distributions based on observed rewards and preconceived notions, it strikes a balance between exploration and exploitation. Thompson Sampling works well in situations where RL agents want to discover the best policies through interactions with the outside world and rewards.