


18
AprUnsupervised Learning
01 Jun 2023
Beginner
2.26K Views
9 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Unsupervised Learning
Introduction
A branch of machine learning known as "unsupervised learning" focuses on the extraction of structures and patterns from unlabeled data. Unsupervised learning algorithms operate on unstructured data without any predetermined categories or labels, in contrast with supervised learning, where input data is labeled with corresponding intended outputs. Unsupervised learning's main objective is to find innate patterns, correlations, and structures in the data so that the model may develop and generate predictions without explicit direction.
Unsupervised learning uses algorithms to search for hidden clusters, patterns, or groups within the dataset. The model is able to comprehend the fundamental structure of the data since these clusters are built based on the intrinsic differences or similarities among the data points. Since the main goal of unsupervised learning algorithms is to explore the data and gain insights, no single target variable needs to be anticipated.
Unsupervised learning employs a variety of methods, such as generative modeling, dimensionality reduction, and clustering. Similar data points are grouped together to form different clusters via clustering techniques like k-means clustering or clustering with a hierarchical structure. Methods for reducing the number of dimensions of the data while maintaining its system include principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE). To simulate the underlying distribution of the data and produce fresh samples, generative models like autoencoders and Gaussian mixture models (GMMs) are used.
Unsupervised learning has numerous uses in a variety of fields. It can be used for a variety of activities where finding patterns and structures in sizable, unlabeled datasets is essential, including segmentation of consumers in marketing, identifying suspicious activity in cybersecurity, recommendation systems in e-commerce, picture and text categorization, and many more.
Because there aren't any ground truth labels, evaluating the findings is one of the key difficulties with unsupervised learning. The effectiveness of the identified patterns or clusters is frequently evaluated using evaluation metrics & domain expertise.
Unsupervised Learning
An algorithm is developed on data that is unlabeled without a specific target variable in a process known as "unsupervised learning" in machine learning. Without the aid of human-labeled examples, the algorithm's goal in unsupervised learning is to identify fundamental patterns, structures, or correlations in the data.
Unsupervised learning's major objective is to draw out important information and findings from the data, revealing hidden patterns that might not be immediately obvious. Unsupervised learning concentrates on examining the innate structure of the data itself, as opposed to supervised learning, when the algorithm learned from labeled data to create predictions or classifications.
Unsupervised learning algorithms use a variety of methods to accomplish their goals. In order to find clusters and subgroups within the data, clustering is a typical approach that groups comparable data points together according to their traits or attributes. Another technique used in unsupervised learning is dimensionality reduction, which seeks to reduce the number of variables and features while maintaining crucial details and data structure. High-dimensional data can be visualized and understood with the aid of this. In order to predict the underlying distribution of the data & produce new samples that closely resemble the original data, generative models are frequently used in unsupervised learning.
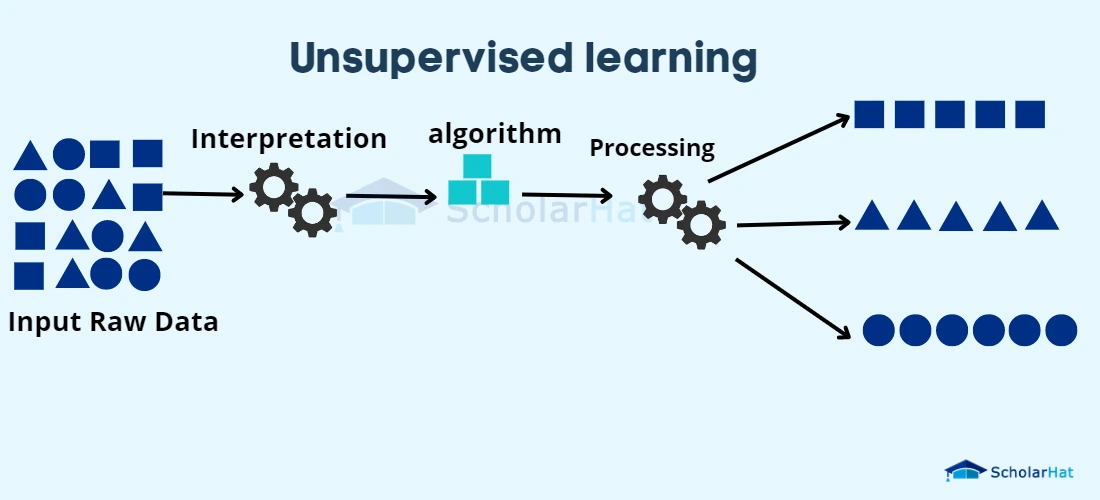
Why use Unsupervised Learning?
Machine learning uses unsupervised learning for a variety of purposes, including:
- Unsupervised learning gives us the opportunity to study and comprehend the fundamental structure of the data. We get insights into the underlying qualities of the data by seeing patterns, correlations, and similarities within unlabeled data, which might reveal essential details about the problem area.
- Detection of abnormalities: Unsupervised learning is useful for locating abnormalities or outliers in the data. Any variations from these patterns can be reported as anomalies, suggesting potential fraud, errors, or strange behavior, by understanding the typical patterns & structures within the data.
- Clustering & segmentation: Unsupervised algorithms for learning can classify data points into clusters or segments based on how similar they are to one another. This helps us identify separate groups of clients that share similar behaviors, tastes, or traits while performing jobs like customer segmentation. For the purpose of classifying related objects or documents, clustering can also be used on picture or text data.
- Dimensionality Reduction: Methods for unsupervised learning that reduce the dimensionality of high-dimensional data include principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE). We can streamline the analysis, better visualization, and potentially improve the performance of subsequent machine learning models by collecting the key features or representations of the data.
- Generative modeling and data synthesis: Through the use of unsupervised learning, generative models may be built that discover the underlying distribution of the data. These models can then produce fresh samples with the same distribution, leading to the creation of new data points. When there is a lack of labeled data, creating more synthetic data can help expand the training set, which can be useful.
- Preprocessing and Feature Engineering: Unsupervised learning methods can help with jobs involving feature engineering and data preprocessing. To simplify the data representation, clustering methods, for instance, can be used to find and eliminate redundant or highly linked features. Prior to using supervised learning methods, unsupervised learning can aid with data normalization or imputing missing values.
- Data visualization: Unsupervised learning techniques make complex, high-dimensional data easier to see. We can produce visual representations that help humans comprehend and analyze the data by reducing the amount of dimension or clustering the data.
Types of Unsupervised Learning
Typical types of unsupervised learning used in machine learning include the following:
- Clustering: Based on their inherent characteristics or closeness, clustering algorithms put comparable data points together. K-means clustering, hierarchical clustering, DBSCAN (Density-Based Spatial Clustering of Applications with Noise), and Gaussian Mixture Models (GMMs) are some common clustering algorithms.
- Dimensionality Reduction: Techniques for dimensionality reduction try to keep the most important data in a dataset while reducing the number of different variables or features. These techniques aid in deriving useful representations from high-dimensional data and visualizing it. Common dimensionality reduction methods include Principal Component Analysis (PCA), t-SNE (t-Distributed Stochastic Neighbour Embedding), and autoencoders.
- Anomaly Detection: Algorithms for identifying instances in a set of data that are uncommon or abnormal or that dramatically depart from the norm. They are helpful for spotting abnormalities, questionable trends, or outliers. Statistical methods like Z-score or Mahalanobis distance as well as more complex algorithms like Isolation Forest and One-Class Support Vector Machines (SVMs) are common anomaly identification strategies.
- Association Rule Learning: These algorithms look for intriguing connections or correlations between various elements in a dataset. These techniques are frequently applied in recommendation systems or market basket analyses. For association rule mining, two popular algorithms are FP-growth and Apriori.
- Generative models: These models are able to create fresh samples that are comparable to the training data while also learning the fundamental probability distribution of the data. These models are helpful for projects like data augmentation, image generation, and text generation. Variational Autoencoders (VAEs) & Generative Adversarial Networks (GANs) are two common generative models.
- Density estimation: Algorithms for density estimation calculate the data's underlying probability density function, which aids in understanding the distribution and organization of the dataset. Common density estimation methods include Kernel Density Estimation (KDE) & Gaussian Mixture Models (GMMs).
Application of unsupervised learning includes
In machine learning, unsupervised learning has numerous uses in a variety of fields. Application of unsupervised learning includes:
- Clustering & Customer Segmentation: Based on a customer's behavior, preferences, or other attributes, unsupervised learning technologies can group like consumers together. This makes it possible for firms to carry out focused marketing, create customized recommendations, and mold their offerings to particular clientele groups.
- Detecting anomalies in datasets: unsupervised learning techniques are useful for finding outliers or anomalies. This is helpful in situations when seeing unexpected patterns or behaviors is crucial, such as fraud detection, network intrusion detection, discovering manufacturing flaws, etc.
- Dimensionality Reduction and Visualisation: Data can be reduced in dimension and visualized in lower-dimensional areas using unsupervised learning methods like PCA and t-SNE. Data exploration, visualization, and comprehension of complicated datasets are all aided by this.
- Recommender Systems: The development of recommendation systems relies heavily on unsupervised learning. Unsupervised learning algorithms can make recommendations for goods, movies, or materials that are catered to specific tastes by looking at user behavior and item similarities.
- Topic Modelling: Predictive topics within collections of texts can be found using unsupervised learning methods like Latent Dirichlet Allocation (LDA). This is advantageous for operations like sentiment analysis, document clustering, text classification, and information retrieval.
- Data Preprocessing: Unsupervised learning methods help with tasks like imputing missing values, normalizing data, and locating and deleting redundant or pointless characteristics. The quality and applicability of the data for subsequent machine learning tasks are improved by these preprocessing stages.
- Generative Modelling: Unsupervised learning makes it possible to train generative models that discover the distribution of the underlying data. This is utilized for things like creating synthetic data, creating images, creating text, and enhancing data.
- Image and video analysis: Without explicit labeling, unsupervised learning algorithms can automatically identify patterns, features, or objects in photos or movies. This is helpful for applications like object detection, image clustering, image segmentation, and content-based image retrieval.
- Bioinformatics and genomics: Unsupervised learning learning is used to analyze biological & genomic data, such as DNA sequences and gene expression profiles. It aids in the discovery of gene clusters, the classification of disorders, and the comprehension of biological mechanisms.
- Market Research & Trend Analysis: By examining consumer behavior, social media sentiment analysis, identifying market trends, and forecasting consumer preferences, unsupervised learning algorithms help with market research.
Summary
Unsupervised learning is a branch of machine learning that focuses on sifting through unlabeled data to find patterns and structures. Unsupervised learning algorithms use unstructured or unannotated data to find underlying patterns and relationships, as opposed to supervised learning, which uses labeled data for training. Types of Unsupervised Learning come in a variety of forms, such as clustering, reduction of dimensions, rule-based association learning, identifying anomalies, generative modeling, and self-organizing maps.
The application of unsupervised learning includes many different fields. Customer segmentation, anomaly detection, reduction of dimensionality, recommender systems, topic modeling, data preprocessing, generative modeling, image and video analysis, bioinformatics, genomics, market research, & trend analysis are just a few applications for which it is utilized. Businesses may make data-driven decisions, acquire useful insights from data, and enhance processes and services by utilizing unsupervised learning techniques.
Unsupervised learning offers many benefits. In addition to allowing for data visualization, it also enables data exploration and interpretation, anomaly detection, grouping & segmentation, reduction of dimensionality, generative modeling, preprocessing, and feature engineering. Because there are no ground truth labels, evaluating the outcomes of learning that is unsupervised can be difficult and necessitates the use of assessment measures and domain expertise.