

11
AprTop 50 MongoDB Interview Questions and Answers
04 Sep 2025
Question
30.3K Views
35 min read

Learn with an interactive course and practical hands-on labs
Free MongoDB Course with Certification
MongoDB Interview Questions and Answers: An Overview
MongoDB is a document-oriented database. MongoDB is a powerful, scalable, and much more flexible database that provides high performance in case of a large volume of data and also leads to a NoSQL Database. MongoDB stores the data in a BSON format. This MongoDB tutorial contains the top 50 frequently asked MongoDB Interview Questions and Answers, to prepare you for the interview.
To sharpen your MongoDB commands, take a look at our:
1. What is MongoDB?
Mongo-DB is a document database with high performance, high availability, and easy scalability. It is an open-source NoSQL database written in C++ language.
2. What is NoSQL Database?
NoSQL stands for Not Only SQL. NoSQL is a category of Database Management System (DBMS) that maintains all the rules of traditional RDBMS systems. It also does not use the conventional SQL syntaxes to fetch the data from the database. This type of database system is typically used in case of a very large volume of data. Some of the well-known NoSQL database systems are – Cassandra, BigTable, DynamoDB, MongoDB, etc.
3. What are the types of NoSQL databases?
There are four types of NoSQL Database available:
- Document Database
This type of NoSQL database is always based on a Document-Oriented approach to store data. The main objective of the Document Database is to store all data of a single entity as a document and all documents can be stored as Collections. Some examples of Document Database – are MongoDB, CosmosDB, CouchDB, PostgreSQL, etc.
- Key-Value Database
This type of database stores data in a schema-less way since key-value storage is the simplest way of storing data. A key can be a point to any type of data, like an object, string, or any other type of data. The main advantages of these databases are easy to implement and add data into. Example – Redis, DynamoDB, etc.
- Column Store Database
These types of databases store data in columns within a keyspace. The key space is always defined by a unique name, value, and timestamp. Example – Cassandra, BigTable, HBase, Vertica, HyperTable.
- Graph Store Database
These types of databases are mainly designed for data that can be easily represented as graph data. This means that data are interconnected with an undetermined number of data relations between them like family and social relations etc. Example – AllegroDB, GraphDB, OrientDB, Titan.
4. What are the advantages of MongoDB?
The main advantages of MongoDB are:
It can deal with a high volume of data.
5. What are Documents?
The document is the heart of MongoDB. In simple words, the document is an ordered set of keys with associated values. It is similar to the table rows in the RDBMS systems. It always maintains a dynamic scheme so that it does not require any predefined structure or fields.
6. What is Collection?
A collection in MongoDB is a group of documents. If a document is the MongoDB analog of a row in an RDBMS, then a collection can be thought of as the analog to a table.
Documents within a single collection can have any number of different “shapes.”, i.e. collections have dynamic schemas.
Syntax
db.createCollection(name,options)
7. What are Dynamic Schemas?
In MongoDB, Collections always have dynamic Schemas. Dynamic Schemas means the documents within a single collection may contain different types of structure or shapes. For example, both the below documents can be stored in a single collection:
{"message" : "Hello World"}
{"id" : 10, "description" : "India"}
8. What is Mongo Shell?
MongoDB Shell is a JavaScript shell that allows us to interact with MongoDB instances using the command line. It is very useful to perform any administrative work along with any other data operations-related commands. Mongo Shell is automatically installed when we install MongoDB on our computers.
9. List out some features of MongoDB.
- Indexing: It supports generic secondary indexes and provides unique, compound, geospatial, and full-text indexing capabilities as well.
- Aggregation: It provides an aggregation framework based on the concept of data processing pipelines.
- Special collection and index types: It supports time-to-live (TTL) collections for data that should expire at a certain time
- File storage: It supports an easy-to-use protocol for storing large files and file metadata.
- Sharding: Sharding is the process of splitting data up across machines.
10. Where can we use MongoDB?
MongoDB can be used in the following areas:
- Content Management System
- Mobile Apps where data volume is very large and requires high readability of data
- Data Management
- Big Data
11. Which languages does MongoDB support?
Several languages are supported by MongoDB like
12. What data types are supported by MongoDB?
MongoDB supports a wide range of data types in documents. Below are the available data types in the MongoDB.
| Data Types | Descriptions |
| String | It is the most commonly used data type. A string must be UTF-8 valid in MongoDB |
| Integer | It is used to store numeric values. It may be either 32-bit or 64-bit. |
| Boolean | It is used to store Boolean data types. It's valued either true or false. |
| Double | It is used to store floating point values. |
| Arrays | This data type is used to store a list or multiple values in a single key |
| Objects | This data type is used to store embedded data |
| Null | It is used to store null data |
| Date | This data type is used to store the current date or time value in Unix time format. |
13. What is ObjectId in MongoDB?
Each document stored in MongoDB must contain an “_id” key. The default value type of the “_id” is ObjectId. In a single collection, every document always contains a unique value of the “_id” field, so that every document can be identified easily. ObjectId always uses 12 bytes of storage. It always represents 24 hexadecimal digit string values.
Objectld is composed of:
- Timestamp
- Client machine ID
- Client process ID
- 3-byte incremented counter
14. How to add data in MongoDB??
The basic method for adding data to MongoDB is “inserts”. To insert a single document, use the collection’s insertOne method:
> db.books.insertOne({"title" : "ScholarHat"})
For inserting multiple documents into a collection, use the method insertMany. This method enables passing an array of documents to the database.
15. What is Capped Collection in MongoDB?
In MongoDB, Capped collections are fixed-size collections, and insert and retrieve data based on the insertion order. If a collection’s space is full, the oldest records will be overwritten by the new documents in the collection. So, to create a capped collection, the command will be –
db.createCollection(“CollectionName”, {“capped”:true, “size” : 100000})
16. What is the Full-Text Index?
Full-text indexing is a search engine feature that enables you to perform text searches on a collection of documents within a database. Unlike traditional databases that search through text using the ‘LIKE’ query pattern match, full-text search engines tokenize the text in documents and build an index to allow very fast text search capabilities.
Full-Text Index is one of the special types of Index in MongoDB for searching text within the documents. However, this type of indexing is expensive for use concerns. So, creating a full-text index on a busy collection can overload the MongoDB Server. So it is always recommended to use this type of index in an offline mode. To create a full-text index, the command is –
db.<CollectionName>.ensureIndex({“name” : “text”})
17. What is GridFS?
Since in MongoDB, every document size limit is 16 MB. So, if we want to insert any large binary data file, we need to use GridFS. GridFS is a mechanism through which we can store any type of large file data like an audio file, video file image, etc. It is just like a file system to store these large files and also, its related data stored in the MongoDB collection.
18. What is the purpose of using $group?
$group syntax is used to bundle or group the documents of a collection based on one or more fields. So, if we want to group the data that depends on one or more than one field, we need to pass those fields' name within the group method to create a group key and normally the group key name is “_id”.
{"$group" : {"_id" : {"state" : "$state", "city" : "$city"}}}
We can use any type of arithmetic operator with the group command as below –
db.sales.aggregate(
{
"$group" : {
"_id" : "$country",
"totalRevenue" : {"$average" : "$revenue"},
"numSales" : {"$sum" : 1}
}
})
19. What is Replication?
Replication is the process that is responsible for keeping identical copies of our data in multiple servers and is always a recommended process for any type of production server. Replication always keeps our database safe even if the database server crashes or data is corrupted. With the additional copies, MongoDB maintains the copy of the data for disaster recovery, reporting, or backup purposes.
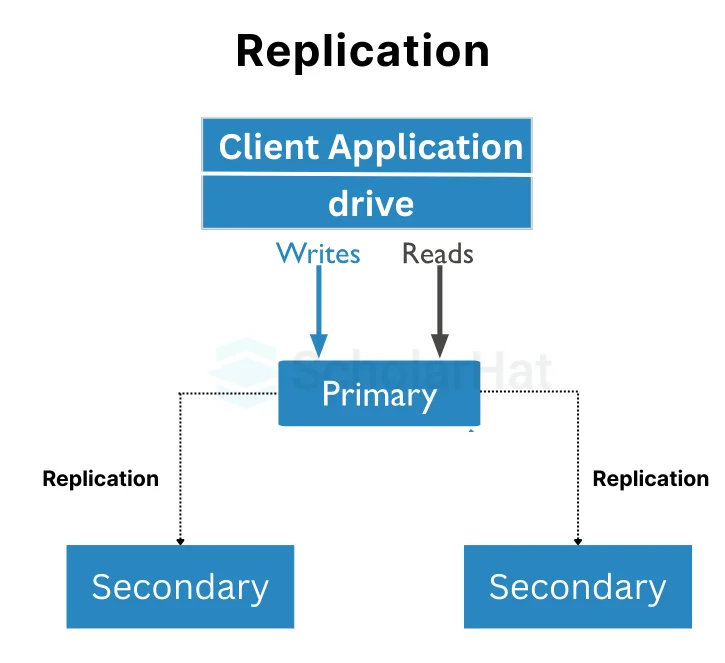
20. Why Replication is required in MongoDB?
In MongoDB, replication is required for the following reasons –
To provide always the availability of data
To secure our application data
Recover the data from any type of disaster recovery
In the Replication process, no downtime requires maintenance like backup, index rebuilds, etc.
Replication can provide us with a read scaling means it will provide us with a copy of data only for real purposes.
21. Explain the replica set.
It is a group of Mongo instances that maintains the same dataset. Replica sets provide redundancy and high availability and are the basis for all production deployments.
22. What is the use of the map-reduce command?
Map-reduce is a way to perform aggregation.
- The Map function emits the key-value pair specified.
- The Reduce function combines the key-value pair and returns the aggregation result.
Syntax
db.collection.mapReduce(
function() {emit(key,value);},
function(key, values) {return aggregatedResult}, { out: collection }
)
23. How to delete a Document in MongoDB?
The CRUD API in MongoDB provides deleteOne and deleteMany for this purpose. Both these methods take a filter document as their first parameter. The filter specifies a set of criteria to match against in removing documents.
Example
> db.list.deleteOne({"_id" : 9})
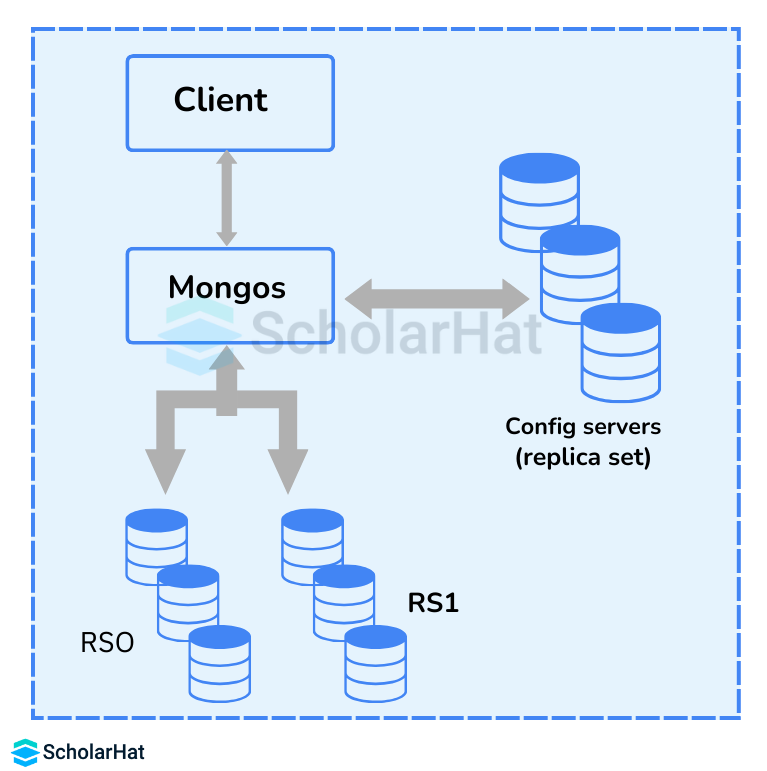
24. Describe the process of Sharding.
Sharding is the process of splitting data up across machines. In other words, it is called “partitioning”. We can store more data and handle more load without requiring larger or more powerful machines, by putting a subset of data on each machine.
In the given figure, RS0 and RS1 are shards. MongoDB’s sharding allows you to create a cluster of many machines (shards) and break up a collection across them, putting a subset of data on each shard. This allows your application to grow beyond the resource limits of a standalone server or replica set.
25. What is the use of the pretty() method?
The pretty() method is used to show the results in a formatted way.
Example
Open your Mongo shell and create one collection with a few documents like the below:
db.list.insertMany([
{_id : 1,name : "ScholarHat",age : 2,"employees" : { "JK" : 1, "SD" : 2 }},
{_id : 2,name : "DotNetTricks",age : 10,"employees" : { "SK" : 3, "PC" : 4 }}
])
db.list.find() It will insert these two documents into the collection list. Now, call db.list.find() to print out all documents in it.
Output
{ "acknowledged" : true, "insertedIds" : [ 1, 2 ] }
{ "_id" : 1, "name" : "ScholarHat", "age" : 2, "employees" : { "JK" : 1, "SD" : 2 } }
{ "_id" : 2, "name" : "DotNetTricks", "age" : 10, "employees" : { "SK" : 3, "PC" : 4 } }
If the data size is too big, it becomes difficult to read. If you call the pretty() method, the result will be like this:
Output
{ "acknowledged" : true, "insertedIds" : [ 1, 2 ] }
{
"_id" : 1,
"name" : "ScholarHat",
"age" : 2,
"employees" : {
"JK" : 1,
"SD" : 2
}
}
{
"_id" : 2,
"name" : "DotNetTricks",
"age" : 10,
"employees" : {
"SK" : 3,
"PC" : 4
}
}
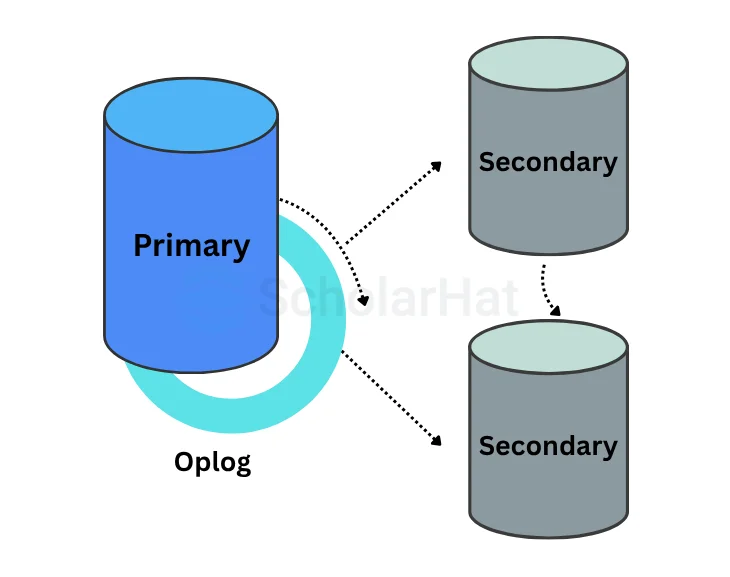
26. Explain the Replication Architecture in MongoDB.
- In the above diagram, the PRIMARY database is the only active replica set member that receives write operations from database clients. The PRIMARY database saves data changes in the Oplog. Changes saved in the Oplog are sequential—i.e., saved in the order that they are received and executed.
- The SECONDARY database is querying the PRIMARY database for new changes in the Oplog. If there are any changes, then Oplog entries are copied from PRIMARY to SECONDARY as soon as they are created on the PRIMARY node.
- Then, the SECONDARY database applies changes from the Oplog to its data files. Oplog entries are applied in the same order they were inserted in the log. As a result, data files on SECONDARY are kept in sync with changes on PRIMARY.
- Usually, SECONDARY databases copy data changes directly from PRIMARY. Sometimes a SECONDARY database can replicate data from another SECONDARY. This type of replication is called Chained Replication because it is a two-step replication process.
27. What is Aggregation in MongoDB?
In MongoDB, aggregations are operations that process data records and return computed results. There are three ways to perform aggregation in MongoDB:
- Aggregation pipeline
- Map-reduce function
- Single-purpose aggregation methods
28. Differentiate MongoDB and RDBMS
| Parameters | RDBMS | MongoDB |
| Definition | It is a relational database management system | It is a non-relational database management system |
| Working | Works on relationships between tables that use rows and columns | A document-oriented system using documents and fields |
| Hierarchical Data Storage | Difficult to store hierarchical data | In-built provision for storing hierarchical data |
| Scalability | Vertically scalable | Vertically and horizontally scalable |
| Performance | Performance increases with an increase in RAM capacity | Performance increases with an increase in processors |
| Schema | Schema has to be pre-decided and designed; changes to the schema are difficult | Dynamic creation and management of schema making the design flexible |
| Support for Joins | Supports complex joins | No support for joins |
| Query Language | Uses SQL for querying the database | BSON is used for database querying |
| Support for Javascript | No support for JavaScript-based clients to query the database | Provision for Javascript-based clients to query the database |
29. Is it possible to run multiple Javascript operations in a MongoDB instance?
Yes, we can run multiple JS operations in a MongoDB instance. Through the Mongo shell instance, we can specify the name of the JavaScript file to be run on the server. The file can contain any number of JS operations.
30. Explain the Storage Engine in MongoDB.
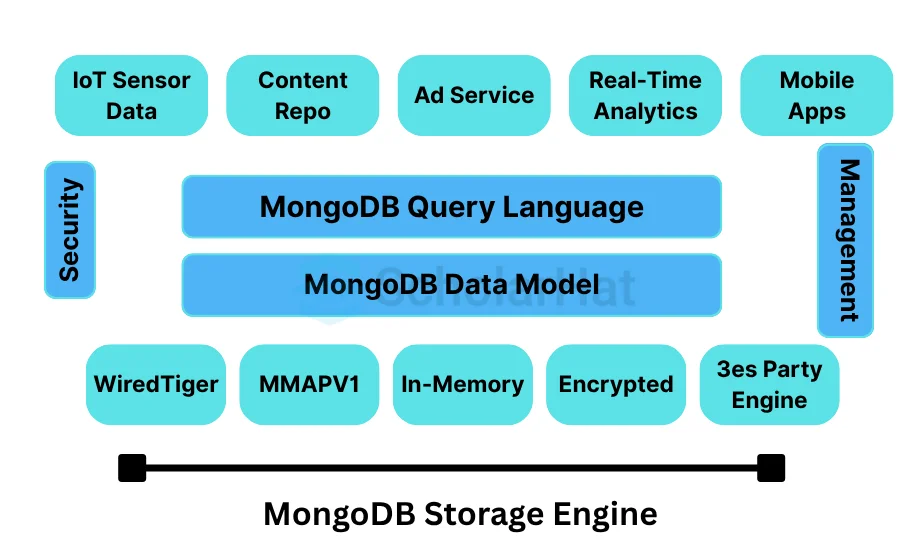
The storage engine is a component of the database that manages how data is stored in both memory and disk. MongoDB provides support for multiple storage engines that help in better performance for different workloads. The default storage engine is WiredTiger (MongoDB3.2), which is well-suited for most workloads.
31. How to perform queries in MongoDB?
The find method is used to perform queries in MongoDB. Querying returns a subset of documents in a collection, from no documents at all to the entire collection.
Syntax
db.collection.find( , , )
The find() method takes the following parameters:
| Parameter | Type | Description |
| query | document | Optional. Specifies selection filter using query operators. To return all documents in a collection, omit this parameter or pass an empty document ({}). |
| projection | document | Optional. Specifies the fields to return in the documents that match the query filter. To return all fields in the matching documents, omit this parameter. |
| options | document | Optional. Specifies additional options for the query. These options modify query behavior and how results are returned. |
Example
db.list.insertMany([
{ "_id": "apples", "qty": 10 },
{ "_id": "bananas", "qty": 19 },
{ "_id": "oranges", "qty": { "in stock": 8, "ordered": 12 } },
{ "_id": "avocados", "qty": "seventeen" }
])
db.list.find( { qty: { $gt: 5 } } )
The above query uses $gt to return documents where the value of qty is greater than 5.
Output
{
"acknowledged" : true,
"insertedIds" : [
"apples",
"bananas",
"oranges",
"avocados"
]
}
{ "_id" : "apples", "qty" : 10 }
{ "_id" : "bananas", "qty" : 19 }
32. What is the difference between the find() and limit() methods?
- find(): displays only selected data rather than all the data of a document. For example, if your document has 10 fields but you want to show only five, set the required field as 5 and others as 0.
Syntax
db.COLLECTION_NAME.find({},); - limit(): limit function limits the number of records fetched. For example, if you have 10 documents but want to display only the first 5 documents in a collection, use the limit.
Syntax
db.COLLECTION_NAME.find().limit(NUMBER);
33. How does MongoDB handle transactions and locks?
MongoDB uses multi-granularity locking to lock operations at the global, database, or collection level. It is up to the storage engines to implement the level of concurrency. For example, in WiredTiger, it is at the document level. For reads, there is a shared locking mode, while for write there is an exclusive locking mode.
34. How to use the $SET Modifier in MongoDB?
$set modifier can be used to set the value of a key, it will be created if the key doesn’t exist and then $set will set the value of that key.
Example
Suppose you have a collection called users, if a particular user updates a particular key like age,
db.users.update({ "_id": ObjectId("58959598byg59595sdwca") }, {
"$set": { "age": 24 }
});
Now the document will have an age key
db.users.findById({ "_id": ObjectId("58959598byg59595sdwca") });
Output
{
"_id": ObjectId("58959598byg59595sdwca"),
"name": "John Doe",
"username": "doe",
"age": 35
}
35. What are the different index types in MongoDB?
- Default: this is the _id that MongoDB creates
- Single field: for indexing and sorting on a single field
- Compound: for multiple fields
- Multi-key: for indexing array data
- Hashed: indexes the hashes of a field value
- Geospatial: to query geospatial(location) data
36. What is meant by Transactions?
A transaction is a logical unit of processing in a database that includes one or more database operations, which can be read or write operations. Transactions provide a useful feature in MongoDB to ensure consistency.
MongoDB provides two APIs to use transactions:
- Core API: It is a similar syntax to relational databases (e.g., start_transaction and commit_transaction)
- Call-back API: This is the recommended approach to using transactions. It starts a transaction, executes the specified operations, and commits (or aborts on the error). It also automatically incorporates error handling logic for "TransientTransactionError" and"UnknownTransactionCommitResult".
37. Illustrate the concept of pipeline in the MongoDB aggregation framework.
An individual stage of an aggregation pipeline is a data processing unit. It takes in a stream of input documents one at a time, processes each document one at a time, and produces an output stream of documents one at a time.
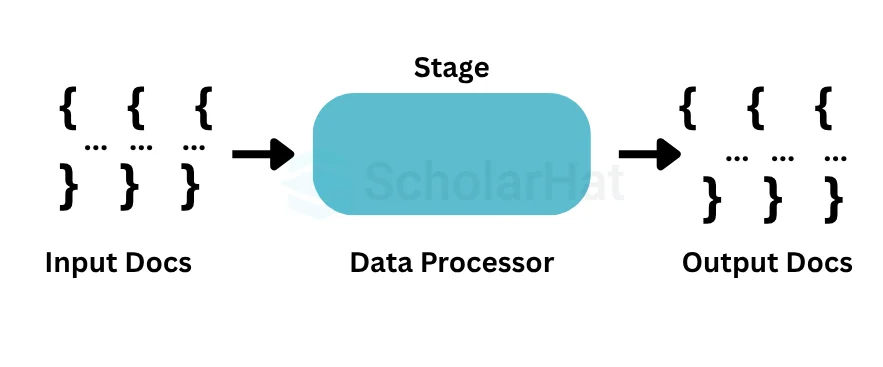
38. What is the role of MongoDB's database profiler?
MongoDB's database profiler is used to analyze the performance of operations against the database, identifying slow queries for optimization. The profiler captures detailed information about the queries, commands, and write operations executed against a MongoDB instance, helping identify slow-running queries, bottlenecks, and performance issues.
39. How is MongoDB better than other SQL information bases?
MongoDB permits an exceptionally flexible and versatile archive structure. For example, one piece of information in MongoDB can have ten segments, and the other one in a similar assortment can have fifteen segments. Likewise, MongoDB information bases are quicker when contrasted with SQL data sets because of proficient ordering and capacity methods.
40. What is an ACID transaction? Does MongoDB support it?
ACID stands for:
- Atomicity
- Consistency
- Isolation
- Durability
The transaction manager ensures these attributes are taken care of. MongoDB version 4.0 supports ACID.
41. How does Scale-Out occur in MongoDB?
The document-oriented data model of MongoDB makes it easier to split data across multiple servers. Balancing and loading data across a cluster is done by MongoDB. It then redistributes documents automatically. The Mongos acts as a query router, providing an interface between client applications and the shared cluster.
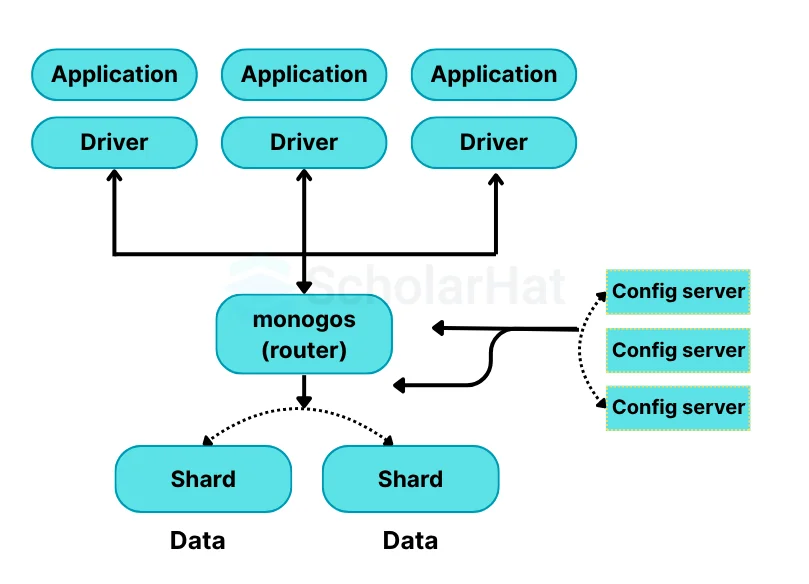
Config servers store metadata and configuration settings for the cluster. MongoDB uses the config servers to manage distributed locks. Each sharded cluster must have its own config servers.
42. Differentiate between MongoDB and Cassandra
| Features | MongoDB | Cassandra |
| Structure of Data | Best database to use when there is no clear structure of the data, i.e. data is a mix of structured and unstructured | Works for both unstructured and structured data, especially when the database is expected to grow dynamically |
| Data Model | Has a rich and expressive data model, which is data-oriented. Any data structure can be easily represented. | Traditional model with rows and columns as in a table. Each column is of a specific type, which makes the structure organized. |
| Number of Master Nodes | There is only one master node in the cluster, which controls many slave nodes. | There are many master nodes in the cluster. |
| Secondary Indexes | It is easy to index any property because the secondary indexes are first-class constructs. | Secondary indexes are limited to single columns and have less flexibility. |
| Scalability | For data to be written in slave nodes, it has to pass through the single master node, so scalability isn’t as good. | Since there are many master nodes, data is present in multiple nodes. Hence, the scalability is comparatively good. |
| Aggregation Framework | Built-in aggregation framework | No built-in aggregation framework |
43. In which format does MongoDB represent document structure?
MongoDB uses BSON to represent document structures.
44. Is MongoDB suitable for representing relationships between data?
MongoDB's schema-less design makes it challenging to represent complex relationships between data. In such cases, developers often need to manually create additional collections to represent these relationships.
45. How does concurrency affect the primary replica set?
When the collection changes are written to primary, MongoDB writes the same to a special collection in the local database, called the primary’s oplog. Hence, both the collection’s database and the local database are locked.
46. Differentiate MongoDB and SQL
| Aspect | MongoDB | SQL |
| Use Cases | Better suited for non-relational data like documents, JSON, and logs. A flexible document-based structure allows for storing different data types without strict schemas | Better for relational data using tables, rows, columns, and relationships. Enforces relational integrity ideal for transactional apps |
| Scalability | Designed to scale horizontally by distributing data across multiple servers. Handles large volumes of reads and writes very well as more servers are added | Not as easy to scale horizontally beyond a single server. Requires more configuration to scale across servers |
| Flexibility | Dynamic schema allows fields within documents to vary. Easy to change data structure over time without modifying DB schema | Requires fixed schema defined upfront. Changes require migrations making it less flexible for evolving data models |
| Complexity | Keeps things very simple with just documents, collections, and databases. Less complex data model and query language | Higher complexity considering data types, keys, indexes, joins, normalization for integrity, and optimized performance |
| Consistency | Eventual consistency model, ensuring availability and partition tolerance in distributed systems | A strong consistency model ensures immediate data consistency across the database |
47. While creating a schema in MongoDB, what points need to be taken into consideration?
While creating a schema in MongoDB, the points that need to be taken care of are:
- Design your schema according to the user's requirements
- Combine objects into one document if we want to use them together; otherwise, separate them
- Do joins while on write, and not when it is on read
- For most frequent use cases, optimize the schema
- Do complex aggregation in the schema
48. Explain the concept of the “upsert” operation in MongoDB.
In MongoDB, “upsert” is a compound of ‘update’ and ‘insert’. It’s an operation that updates existing documents based on certain criteria or inserts a new document if no document matches the criteria. The upsert option in the update() method facilitates this. If set to true, it creates a new document when no document matches the query criteria. This eliminates separate operations for checking the existence and then updating/inserting, making database interactions more efficient.
49. Is it necessary to create a database command in MongoDB?
You don't need to create a database manually in MongoDB because it creates automatically when you save the value into the defined collection the first time.
50. Does MongoDB support foreign key constraints?
No, MongoDB doesn’t support foreign key constraints. Because of the document structure, MongoDB provides flexible ways to define relationships.
| Download this PDF Now - MongoDB Interview Questions PDF By ScholarHat |
Summary
I hope these questions and answers will help you to crack your MongoDB Interview. These interview Questions have been taken from our newly released eBook MongoDB Interview Questions & Answers. This book contains more than 100+ MongoDB interview questions.

If you are preparing for theMongoDB Interview Questions and Answers Book, this MongoDB Interview Questions and Answers Book can really help you. It has simple questions and answers that are easy to understand. Download and read it for free today!
Take our Mongodb skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.