



10
AprSystem Design Roadmap: Step-by-Step
01 Mar 2025
Beginner
3.4K Views
18 min read
Do you want to master system design but don’t know where to start? Don’t worry, you have clicked on the right window! System design might sound complex at first, like thinking about scalability, databases, load balancing, caching, and all that technical stuff. But trust me, with the right approach, you can learn it step by step, even if you're just getting started.
Hence, In this System Design Tutorial, I have brought you the blueprint of the System Design Roadmap. You will also learn about each point included in the system design. So why wait? Let's just start.
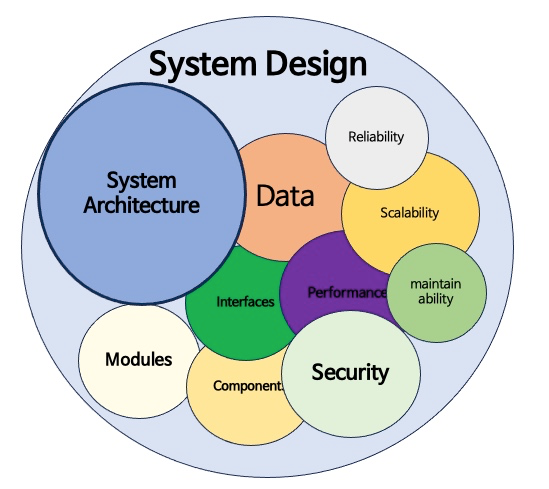
System Design Roadmap
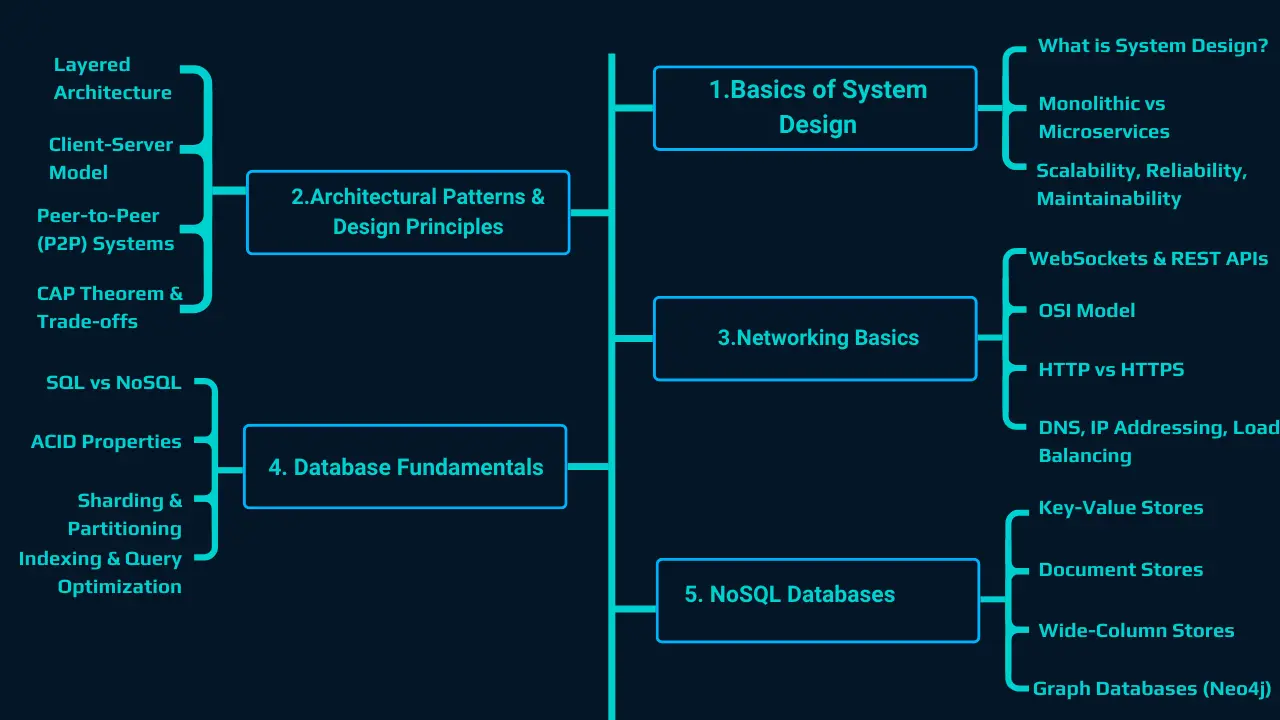
1. Basics of System Design
System design is the process of defining the architecture, components, modules, and data flow of a system to meet business and technical requirements. It involves making decisions on scalability, maintainability, and efficiency to ensure that the system performs well under varying loads. Good system design prevents failures, ensures smooth performance, and enhances user experience. A well-designed system balances cost, performance, security, and reliability effectively. Understanding system design is crucial for building robust and scalable applications.
What is System Design?
System design refers to the high-level structuring of an application or software system. It defines how different parts of the system interact with each other, handle data, and function under load. A good system design ensures efficiency, reliability, and scalability.
1. Importance of Scalability, Reliability, Maintainability in System Design
- Scalability ensures that a system can handle increasing amounts of work by adding resources.
- Reliability guarantees that the system functions correctly under various conditions without failure.
- Maintainability focuses on writing clean, modular, and easy-to-update code that can be improved without breaking the entire system.
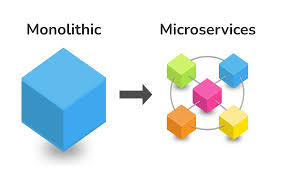
2. Monolithic Vs. Microservices Architecture
- A monolithic architecture is a single, tightly coupled application where all components work together in one codebase.
- On the other hand, Microservices architecture consists of small, independent services that communicate through APIs.
- Monoliths are simpler to develop but harder to scale, whereas microservices are complex but offer better flexibility and scalability.
2. Architectural Patterns & Design Principles
Architectural patterns define the structure of a system and how components interact. Choosing the right architecture is essential for system scalability, flexibility, and maintainability. Different architectures are suited for different use cases, such as layered architecture for enterprise applications, microservices for scalable web apps, and event-driven models for real-time systems.
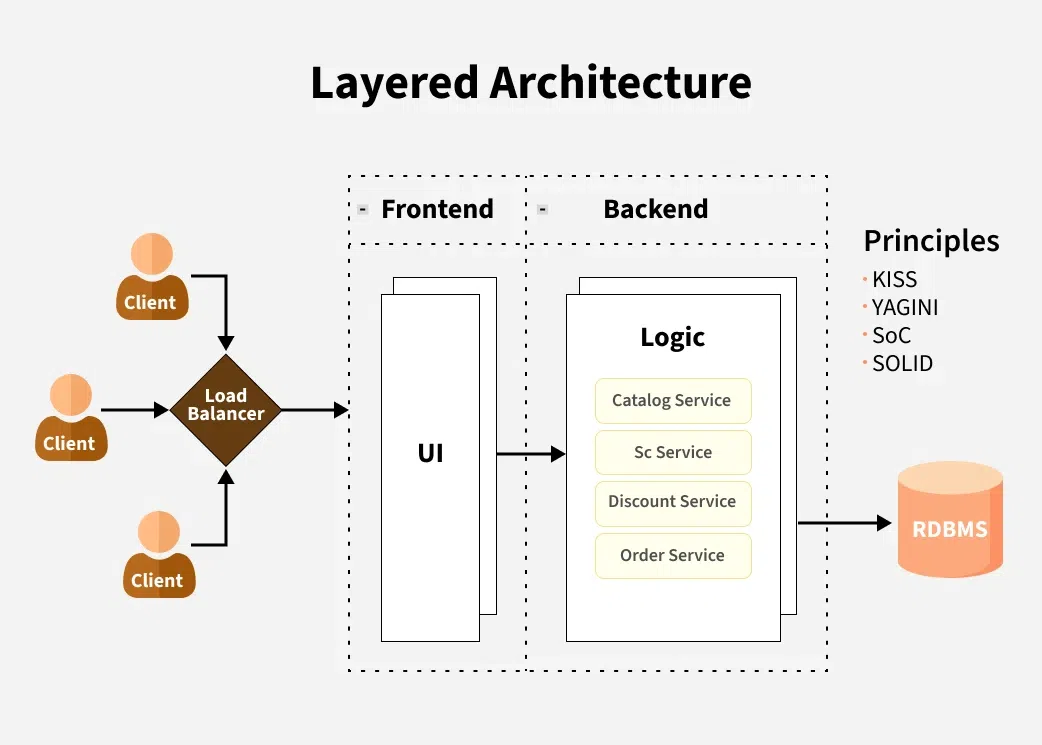
1 Layered Architecture
A layered architecture separates an application into logical layers like presentation, business logic, and data. This improves modularity, code organization, and maintainability. Enterprise applications often use this pattern to better separate concerns.
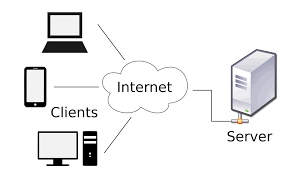
2 Client-Server Model
The client-server model consists of clients (users) sending requests to a server, which processes and returns responses. This model is the foundation of web applications, mobile apps, and cloud services. It enables a clear separation between front-end and back-end functionality.
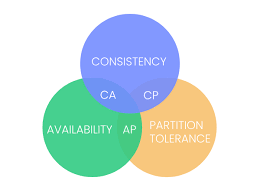
3 CAP Theorem (Consistency, Availability, Partition Tolerance)
CAP Theorem states that in a distributed system, you can only achieve two out of three properties: Consistency (C), Availability (A), and Partition Tolerance (P). Understanding this helps in designing fault-tolerant and scalable databases.
3. Networking Basics
Networking is essential in system design, as applications must communicate over the internet. Understanding protocols, connections, and security measures ensures efficient and secure data transmission. Poor networking design can lead to high latency, security risks, and unreliable communication between services.
1 OSI Model (Application, Transport, Network, etc.)
- The OSI Model defines how data moves through a network in seven layers.
- Each layer handles specific tasks like data transmission (Transport Layer) or addressing (Network Layer). Understanding these layers helps in debugging network issues and optimizing communication.
2 HTTP vs HTTPS
- HTTP (HyperText Transfer Protocol) is used for web communication but lacks encryption.
- HTTPS (Secure HTTP) adds SSL/TLS encryption, protecting data from being intercepted.
- Using HTTPS is critical for securing user data and preventing cyber threats.
3 WebSockets & REST APIs
- REST APIs enable communication between different systems over HTTP.
- WebSockets, on the other hand, provide real-time, bidirectional communication, useful for chat applications and live updates.
- Choosing the right protocol depends on the system’s needs.
4. Database Fundamentals
Databases store and manage application data efficiently. Choosing the right database structure impacts query performance, data integrity, and scalability. Understanding database fundamentals ensures smooth operations and optimal performance under load.
1 SQL vs NoSQL
SQL databases (like MySQL and PostgreSQL) store structured data in tables and use structured query language for transactions. NoSQL databases (like MongoDB, Cassandra) store unstructured data and offer flexibility in schema design. Choosing between them depends on data complexity and scalability needs.
2 ACID Properties
ACID (Atomicity, Consistency, Isolation, Durability) ensures that database transactions remain reliable. These properties prevent data corruption and inconsistencies during operations. ACID compliance is crucial for banking and financial systems.
3 Indexing & Query Optimization
Indexing speeds up database queries by creating quick lookup structures. Query optimization ensures that queries execute efficiently without excessive resource usage. Proper indexing can significantly improve database performance and reduce latency.
5. NoSQL Databases
NoSQL databases provide scalability and flexibility for handling large amounts of unstructured data. They are commonly used in big data applications, real-time analytics, and distributed systems.
1 Key-Value Stores (Redis, DynamoDB)
- Key-value stores store data as key-value pairs, offering fast access to frequently used data.
- Redis and DynamoDB are popular choices for caching and real-time applications.
2 Document Stores (MongoDB, CouchDB)
- Document databases store data as JSON-like documents, making them ideal for applications that require flexible schemas.
- MongoDB and CouchDB are commonly used for content management systems and IoT applications.
3 Graph Databases (Neo4j)
- Graph databases store relationships between data efficiently, making them ideal for social networks, recommendation systems, and fraud detection.
- Neo4j is one of the most widely used graph databases.
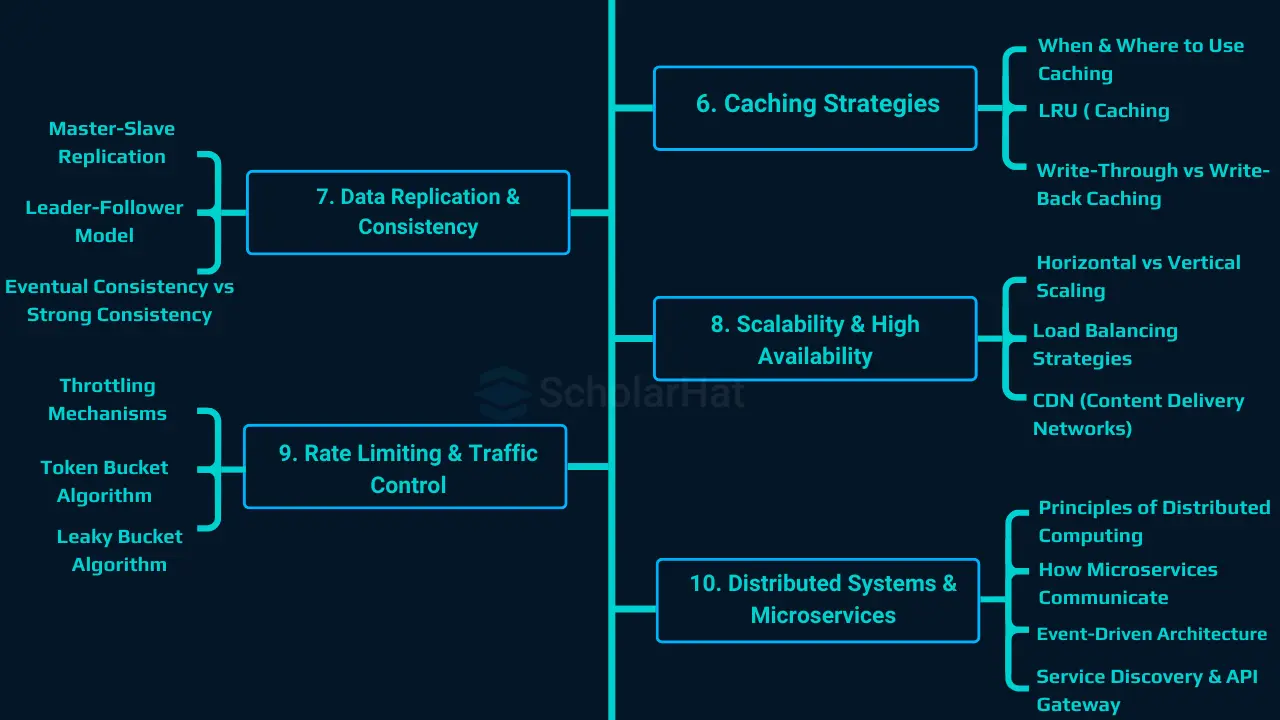
6. Caching Strategies
Caching improves performance by storing frequently accessed data closer to the user. Different caching strategies include:
1. Cache-aside (Lazy Loading)
- Data is fetched from the database only if not found in the cache.
- Pros: Simple and reduces database load.
- Cons: First-time access is slow.
2. Write-through Caching
- Data is written to both the cache and database simultaneously.
- Pros: Ensures consistency.
- Cons: Slower writes.
3. Write-back Caching
- Data is written to the cache first and later updated in the database.
- Pros: Faster writes.
- Cons: Risk of data loss if cache fails.
4. Read-through Caching
- The cache fetches data from the database automatically when needed.
- Pros: Simplifies application logic.
- Cons: More complex cache setup.
5. Refresh-ahead Caching
- The cache is updated proactively before data expires.
- Pros: Reduces cache misses.
- Cons: Unnecessary updates may occur.
7. Data Replication Consistency
Data replication ensures that copies of data exist across multiple servers, but maintaining consistency is crucial.
Types of Consistency
1. Strong Consistency
- All replicas see the same data at the same time.
- Example: MySQL with ACID properties.
2. Eventual Consistency
- Updates propagate over time but may be temporarily inconsistent.
- Example: NoSQL databases like DynamoDB.
3. Causal Consistency
- Ensures related updates are seen in the correct order.
4. Read-Your-Writes Consistency
- A user always sees their own updates immediately.
5. Monotonic Reads Consistency
- Once data is read, it will never return an older value.
8. Scalability & High Availability
Scalability ensures that a system can handle increased loads without degrading performance.High availability ensures that services remain accessible even during failures.
1 Horizontal vs Vertical Scaling
Horizontal scaling involves adding more machines to distribute load, while vertical scaling involves upgrading existing machines. Horizontal scaling is more cost-effective for handling large-scale traffic.
2 Load Balancing Strategies
Load balancers distribute traffic across multiple servers to prevent overloading. Strategies like Round Robin, Least Connections, and Weighted Load Balancing help optimize resource usage and improve response times.
3 CDN (Content Delivery Networks)
A CDN caches content on multiple global servers, reducing latency and improving performance for users worldwide. CDNs are widely used for video streaming, e-commerce, and large-scale websites.
9. Rate Limiting & Traffic Control in System Design
1. Rate Limiting
Rate limiting controls the number of requests a user, IP, or service can make within a specific time window. It prevents system overload, abuse, and ensures fair usage.
Why is Rate Limiting Needed?
- Prevents DDoS Attacks – Stops malicious users from overwhelming a system.
- Ensures Fairness – Prevents a single user from consuming excessive resources.
- Protects Backend Services – Avoids overloading databases, APIs, or microservices.
- Manages API Usage – Enforces API quotas and pricing models.
Rate Limiting Algorithms
- Fixed Window Counter – Uses a counter to track requests within a fixed time window.
- Sliding Window Log – Maintains a log of request timestamps.
- Sliding Window Counter – Uses a rolling counter for better distribution.
- Leaky Bucket – Requests are processed at a fixed rate.
- Token Bucket – Allows bursty traffic up to a limit.
2. Traffic Control
Traffic control mechanisms regulate how traffic flows in a distributed system to optimize performance and reliability.
Traffic Control Techniques
- Load Balancing – Distributes incoming traffic across multiple servers.
- Circuit Breaker – Stops requests to failing services.
- Rate-Based Throttling – Slows down requests instead of blocking them.
- Queue-based processing – Uses message queues to handle high-load spikes.
- Priority-Based Routing – Assigns priority levels to requests.
Where is Rate Limiting & Traffic Control Applied?
- APIs (REST, GraphQL, gRPC)
- Microservices
- CDNs
- Authentication Systems (OAuth, JWT)
- Search & Recommendation Engines
- Cloud Services (AWS, GCP, Azure)
Best Practices
- Implement rate limiting at API Gateway.
- Use distributed caches (Redis) for tracking request counts.
- Combine rate limiting with authentication & role-based access.
- Provide error messages with retry-after headers.
- Use monitoring tools like Prometheus & Grafana.
10. Distributed Systems and Microservices
Distributed systems and microservices are foundational concepts in modern software architecture, enabling scalability, fault tolerance, and flexibility.
Distributed Systems
- Definition: A distributed system is a collection of independent computers that appear to the user as a single coherent system.
- Key Characteristics:
- Concurrency: Multiple components run simultaneously.
- No Global Clock: Coordination without a shared clock.
- Independent Failures: Components fail independently.
- Challenges:
- Consistency: Ensuring data consistency across nodes (e.g., CAP theorem).
- Partition Tolerance: Handling network partitions.
- Latency: Managing communication delays.
- Examples: Distributed databases (e.g., Cassandra), distributed file systems (e.g., HDFS), and distributed computing frameworks (e.g., Hadoop).
Microservices
- Definition: Microservices is an architectural style where an application is composed of small, independent services that communicate over well-defined APIs.
- Key Principles:
- Single Responsibility: Each service focuses on a specific business capability.
- Decentralization: Services are independently deployable and scalable.
- Polyglot Persistence: Use of different databases for different services.
- Benefits:
- Scalability: Scale individual services as needed.
- Fault Isolation: Failures in one service don’t affect others.
- Faster Development: Teams can work independently on different services.
- Challenges:
- Inter-Service Communication: Managing APIs, latency, and retries.
- Data Consistency: Ensuring eventual consistency across services.
- Operational Complexity: Monitoring, logging, and debugging across services.
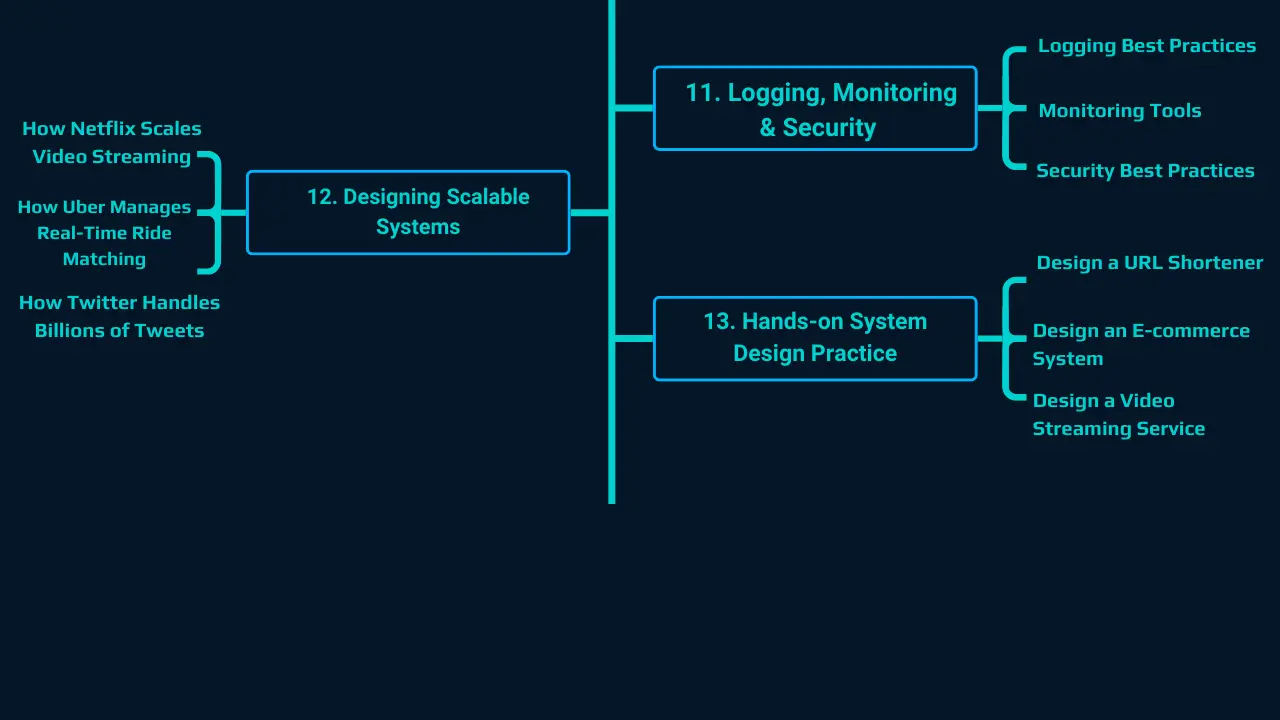
11. Logging, Monitoring, and Security
These are critical operational aspects of any distributed system or microservices architecture.
Logging
- Purpose: To capture and store events and activities in the system for debugging, auditing, and analysis.
- Best Practices:
- Structured Logging: Use JSON or key-value pairs for easy parsing.
- Centralized Logging: Aggregate logs from all services (e.g., using ELK Stack or Splunk).
- Log Levels: Use appropriate levels (e.g., INFO, DEBUG, ERROR) for granularity.
- Retention Policies: Define how long logs are stored based on compliance and utility.
Monitoring
- Purpose: To observe the health, performance, and availability of the system in real-time.
- Key Metrics:
- Infrastructure Metrics: CPU, memory, disk usage.
- Application Metrics: Request rates, error rates, latency.
- Business Metrics: User activity, conversion rates.
- Tools: Prometheus, Grafana, Datadog, New Relic.
- Alerting: Set up alerts for anomalies (e.g., high error rates, downtime).
Security
- Purpose: To protect the system from unauthorized access, data breaches, and other threats.
- Key Practices:
- Authentication and Authorization: Use OAuth, JWT, or RBAC.
- Encryption: Encrypt data in transit (TLS) and at rest (AES).
- API Security: Validate inputs, use rate limiting, and protect against DDoS attacks.
- Compliance: Adhere to regulations like GDPR, HIPAA, etc.
- Tools: Vault for secrets management, firewalls, and intrusion detection systems.
12. Designing Scalable Systems
Scalability is the ability of a system to handle an increased load without compromising performance.
Types of Scalability
- Vertical Scaling: Adding more resources (CPU, RAM) to a single node.
- Horizontal Scaling: Adding more nodes to the system.
Scalability Patterns
- Load Balancing: Distribute traffic across multiple servers (e.g., using NGINX, HAProxy).
- Caching: Reduce database load by caching frequently accessed data (e.g., Redis, Memcached).
- Database Scaling:
- Read Replicas: Distribute read queries across replicas.
- Sharding: Partition data across multiple databases.
- Stateless Services: Design services to be stateless for easy scaling.
- Message Queues: Use queues (e.g., Kafka, RabbitMQ) to decouple services and handle bursts.
Scalability Challenges
- Consistency vs. Availability: Trade-offs in distributed systems (CAP theorem).
- Bottlenecks: Identify and address performance bottlenecks.
- Cost: Scaling can be expensive; optimize resource usage.
13. Hands-On System Design Practice
Practical experience is essential to master system design. Here’s how to approach it:
Steps for System Design Practice
- Understand Requirements:
- Functional (what the system should do).
- Non-functional (scalability, latency, availability).
- Define Scope:
- Focus on core features first.
- Avoid over-engineering.
- High-Level Design:
- Draw a block diagram of components (e.g., API Gateway, Services, Databases).
- Define data flow and interactions.
- Deep Dive into Components:
- Choose appropriate databases (SQL vs. NoSQL).
- Decide on communication protocols (REST, gRPC, WebSockets).
- Plan for caching, load balancing, and fault tolerance.
- Scalability and Optimization:
- Estimate traffic and storage requirements.
- Plan for horizontal scaling and sharding.
- Error Handling and Edge Cases:
- Plan for failures (e.g., retries, circuit breakers).
- Handle edge cases (e.g., race conditions, data inconsistencies).
Common System Design Problems in Practice
- Design a URL-shortening service (e.g., TinyURL).
- Design a social media feed (e.g., Twitter).
- Design a ride-sharing app (e.g., Uber).
- Design a distributed cache (e.g., Memcached).
- Design a notification system (e.g., WhatsApp).
Tools for Practice
- Diagramming: Draw.io, Lucidchart.
- Prototyping: Use cloud platforms (AWS, GCP) to build and test designs.
- Mock Interviews: Practice with peers or platforms like Pramp.
Summary
Designing robust, scalable, and efficient systems is a critical skill for software engineers, especially as applications grow in complexity and user demand. The System Design Roadmap provides a structured approach to mastering this skill, covering essential concepts such as distributed systems, microservices, logging, monitoring, security, and scalability. The system design roadmap provides a step-by-step guide to mastering the art of building scalable and efficient distributed systems.
FAQs
The roadmap is ideal for:
- Software engineers preparing for technical interviews.
- Developers transitioning to senior or architect roles.
- Anyone interested in building scalable and distributed systems.
The roadmap typically includes:
- Distributed systems and microservices.
- Scalability, availability, and reliability.
- Database design (SQL, NoSQL, sharding, replication).
- Caching, load balancing, and message queues.
- Logging, monitoring, and security.
- Hands-on system design practice.
The duration depends on your prior experience and the time you can dedicate. On average, it may take 2-3 months of consistent effort to cover all topics and practice sufficiently.
While basic programming and software development knowledge is helpful, the roadmap is designed to guide beginners and experienced developers alike. Start with foundational concepts and gradually move to advanced topics.
Take our Systemdesign skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.